




盛科的新Baby–ManhattanTM和BrooklynTM
作者 陈怀临 | 2011-04-19 07:38 | 类型 专题分析, 芯片技术 | 43条用户评论 »
|
【陈怀临:恭喜盛科。下面是我拿到的新闻稿。及时的给同学们汇报。后续分析会陆续展开。。。。。。】 苏州2011年4月19日电 /美通社亚洲/– 盛科网络(苏州)有限公司(以下简称“盛科”),是领先的核心芯片及定制化网络解决方案的提供商,日前宣布将于2011年第三季度推出两款以太网交换核心芯片 CTC6028(ManhattanTM)和CTC5048 ( BrooklynTM ),从而与现有的 CTC6048(HumberTM )包交换核心芯片和 CTC8032 ( RichmondTM )交换网核心芯片一起,构建完整的以太网交换芯片产品系列 TransWarpTM。该产品系列,为网络设备提供商构建从固定配置的盒式系统到模块化分布式架构的网络设备提供了全面、有竞争力和差异化的芯片解决方案。 CTC6028和 CTC5048均采用65nm CMOS 工艺,拥有业界领先的集成度,内部集成包处理引擎、流量管理引擎和上联接口,在功耗方面有着良好的表现。CTC6028提供68Gbps的处理能力,具备外接 TCAM 和 SRAM 的表项扩展能力,在满足电信和企业高密度汇聚网络的高扩展,高性能应用要求的同时,最大程度降低设备成本。CTC5048提供与 CTC6048相同的100Gbps 的处理能力,可满足企业和电信城域汇聚应用的高性价比要求。 CTC6028和 CTC5048沿用了盛科 CTC6048独特而灵活的产品架构,提供集Ethernet/IP/MPLS/MPLS-TP 于一体的融合设计,可以满足当前和未来多种业务和网络承载需求。以下是这两款芯片的重要特性: 基于 CTC6048开发的软件可无缝移植到基于 CTC6028与 CTC5048的硬件平台上。目前,完整的具备L2/L3/MPLS 特性的 CTC6048参考设计已经开始供应给客户测试。基于 CTC6028与CTC5048的软件设计亦可以基于此评估板进行设计。 美国 Linley Group 的高级分析师 Jag Bolaria 表示:“以太网承载在3G/4G 移动通讯网络,视频网络,数据中心和云计算领域的应用越来越普及。盛科的 TransWarp 芯片系列为城域以太网和数据中心网络等应用领域提供了极具竞争力的产品。它能很好的帮助 OEM 厂商根据自身需要构建从边缘设备到核心设备的差异化网络解决方案,并且可以基于统一的芯片架构进行软件复用。” “这两款芯片的问世,标志着盛科 TransWarp 产品线的进一步丰富,能够为三网融合、城域以太网接入和汇聚网络、分组传送网络(PTN)、光线路终端设备(OLT)等多种应用提供更多高性价比的核心芯片。”盛科首席技术官古陶表示。“盛科还将发布一系列基于下一代技术的高性价比的接入和汇聚芯片,从而覆盖更多的细分市场,可为设备商提供更加完整的解决方案。” | |
 (4个打分, 平均:5.00 / 5) (4个打分, 平均:5.00 / 5) |
二层多路径环境中的网关负载
作者 tree | 2011-04-19 07:30 | 类型 行业动感 | 84条用户评论 »
|
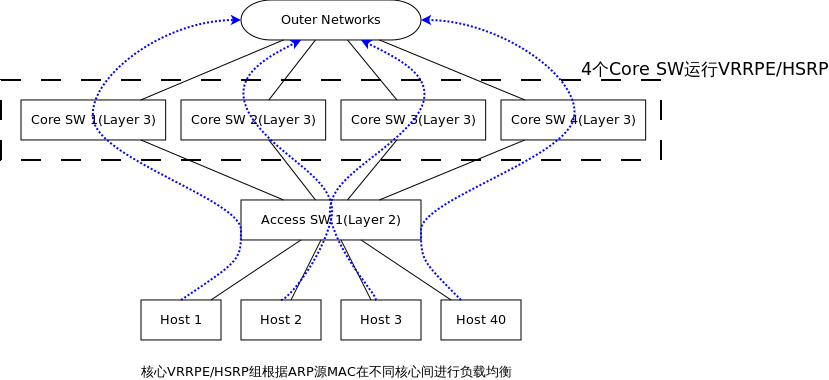
在目前的数据中心解决方案中,二层多路径应该是一个大趋势,它可以消除环路,同时还能提供多路径负载。 但二层多路径中网关的设置在目前的方案中却提的比较少,收集了一些信息,目前的解决方案主要: 第一种方案,TRILL/SPB + VRRPE/HSRP
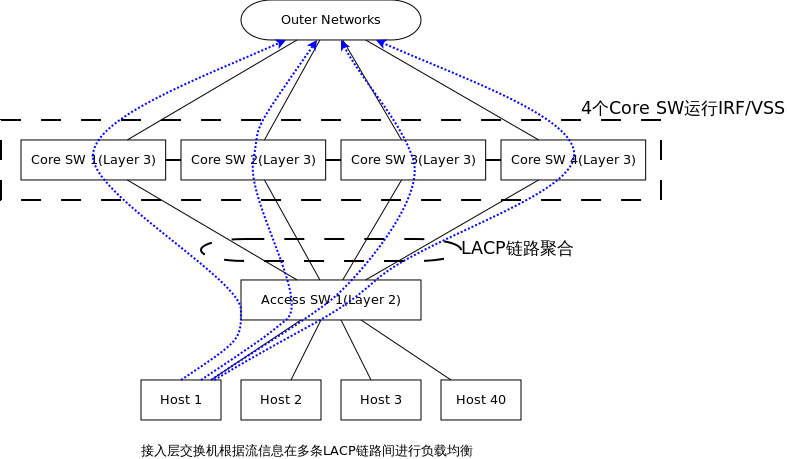
在这张图中看不出来存在环路,这是因为只画了一台接入层交换机,如果存在N台接入层交换机,Core之间就存在二层环路了,TRILL/SPB可以使任何一个接入层交换机到4个Core的链路都处于转发状态,4个Core之间可以运行VRRPE/HSRP,使4台Core都可以转发,VRRPE/HSRP的负载均衡模式是基于ARP应答: 1. 如Host 1请求GW的ARP,应答Core 1 MAC,依次类推,每个Host都有属于自己的1个GW访问外部网络 2. 当Core 2连接Outer Network断开,会降低其权重,通知其余同伴自己失去了能力,这时同伴首领如Core 1可以立即发送一个ARP刷新所有Host上GW ARP,將发往Core 2的流量引向其余Core 第二种方案,不使用TRILL/SPB,使用IRF/VSS等N->1虚拟化技术,这是目前在TRILL/SPB标准尚未成熟的解决方案:
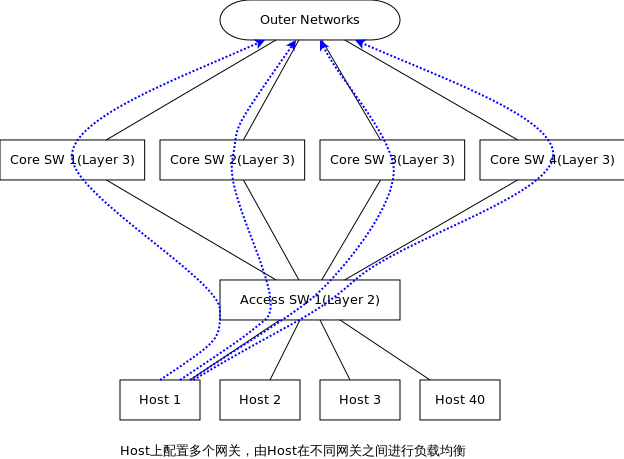
这种方式的特点: 1. 多个Core通过专属互联,运行私有协议虚拟化成1台物理设备,这种虚拟化和服务器的1->N虚拟化正好相反 2. 当Core 1连接Outer Networks歇B,由于4个Core已经虚拟成1台设备,所以流量会自动切换到 3. 接入层交换机上联的4个Core的链路就变成连接到1台物理设备,所有接入层交换机和虚拟物理设备之间可以运行LACP进行链路聚合,在逻辑连接上消除了环路隐患,这种方案中Host的GW也是1台虚拟化的设备,负载均衡在接入层交换机和虚拟核心的LACP链路上,负载均衡要素可以是5元组、7元组等等,负载均衡的灵活性上要比第一种方案要好,但IRF/VSS都是私有化技术,并不被业界所喜欢。 第三种方案是在第一种方案基础上,抛弃VRRPE/HSRP,而是在Host上配置多个GW,也就是说把3层负载均衡交给Host来做:
1. Host上分别配置4个默认GW,分别是Core 1~4的IP地址,就和路由器有4条默认路由的ECMP情况一致,4条路由都处于激活状态,Host可以根据Application在4个GW之间负载均衡,也可以指定其余顺序使用策略,负载灵活性上要比前2种方案都高。这种方式对操作系统也是蛮大的,但基于Linux的Server数量多,又可以改造,应该也是可行的方案。 2. 问题是当Core 1外联Outer Network歇B,怎么样切换到其余Core上,Core之间差不多完全独立,所以只能是Core 1告诉Host失去能力了,找其它Core吧,那么当Core 1又恢复了怎么办?Core 1再通知Host?前一个问题可以通过”信任制ICMP destination unreachable-route”来搞定,第二种情况就只能单独开发一套系统了,差不多是一种GW与Host之间的轻量级路由协议,这估计是这个方案的最大挑战。 | |
 (1个打分, 平均:3.00 / 5) (1个打分, 平均:3.00 / 5) |
华为赛门铁克N8500集群NAS系统刷新SPEC记录
作者 黄 岩 | 2011-04-18 19:43 | 类型 弯曲推荐, 行业动感 | 131条用户评论 »
|
尊敬的陈首席,存储界发生了一件大事。 下面这个独立评论员写文章,请参考。 (http://www.theregister.co.uk/2011/04/18/hs_specsfs2008_crown/) 陈首席,考验您判断力的时刻到了。如果弯曲评论错过了报道‘存储行业大地震’的机会,您将愧对‘首席科学家’之称号,也必将因此遗恨终生:) 【陈怀临注:华赛已经发展到对人民的首席赤裸裸的威胁。。。首席很生气,后果很严重。我决定,一定亲自赴成都去耍,吃垮华赛的粉丝群。。。。。。】 我现在担任N8500这个产品的性能专项SE,非常愿意在弯曲评论上与大家一起讨论NAS性能和SPECsfs2008测试的相关技术问题,特别是技术细节和调优方法。 黄岩 —–
华为赛门铁克N8500集群NAS存储系统在标准性能评估机构SPEC的 SPECsfs2008测试中性能全球排名第一,打破NFS和CIFS两项业界记录。此次测试也是华为赛门铁克自2009年获得最高测试结果后,再一次刷新SPEC基准测试记录,分别获得636,036 OPS和712,664 OPS的最高性能得分。 SPEC(Standard Performance Evaluation Corporation, SPEC®)标准性能评测机构,是国际上对系统应用性能进行标准评测的权威组织。SPECsfs2008是SPEC组织发布的面向文件服务应用的核心基准,衡量文件访问的吞吐量和响应时间,为比较不同厂商的文件服务器性能提供了一个标准的评测方法。目前已有18家主流NAS制造商通过该评测基准的验证,输出了核心产品的性能数据。 N8500系统属于华为赛门铁克推出的中高端Scale-out NAS产品N8000家族一员,该产品定位于中高端NAS市场。N8000系列集群NAS存储系统架构上采用了多节点全Active集群技术,所有的引擎节点均处在同一个集群,可以协同工作,并发进行事务处理,各引擎节点也可以同时访问同一个文件。其次,N8500系统最多可支持256个单一命名空间,每个命名空间最大可以支持10亿个文件。N8500系统最大可以支持16引擎节点,引擎节点的数量扩展可带来系统性能上的线性增长。本次发布的性能值是使用 8个引擎节点达到的SPEC测试数据,因此系统整体性能依然具有很大的扩展潜力。 华为赛门铁克科技有限公司副总裁范瑞琦表示:“N8500集群NAS存储系统具有高性能、可扩展性和可获得性的特点,是我们的旗舰型产品。我们一直致力于产品开发并持续保持竞争力,连续破纪录的基准测试结果也证明了N8500系统是业界最高性能的产品。与友商产品相比,N8500系统能够帮助客户采用更低的运营成本,而获得更高的性能”。 关于SPECsfs2008基准 | |
|
(9个打分, 平均:4.11 / 5) |
工具箱
本文链接 |
|
打印此页 | 131条用户评论 »
浅谈高端CPU Cache Page-Coloring(2)
作者 陈怀临 | 2011-04-17 11:12 | 类型 专题分析 | 44条用户评论 »
系列目录 高端CPU Cache Page Coloring为了理解Page Coloring,需要把握或者记住下面几点: 在上述3个前提下,如果理解Page Coloring? 思考了好几天,如何用大白话来说,而非玩学术。玩胶片。 我的理解大概是这样的: 理解一:大宋姐妹一盘棋 亮点: 相对均匀的分配落脚点的好处是都整体经济拉通有好处。 理解二:不要输在起跑线上 亮点:人为调整住房和户口【含假离婚(据说最后都变成真离婚)】信息,映射到最好,或者次好的校区。 Coloring的目的就是把一个东西的落脚点,有目的地,设置好,从而获得最大利益。这个设置就是通过在可控的范围内(OS),把物理Page的Page Frame信息调配好,从而最大程度上的利用大Cache。 现在我们来看看CPU的Page和Cache是如何协同工作的。 现在考虑一个L2 Cache,参数如下: 这个2M的L2 Cache有多少SET(集合或者组)? 2M/(32 × 4) = (2 ×2^20)/ (2^5 * 2^2)=2^14=16K=16*1024 这个2M的cache是分成了16384个SET。每个SET里含有和管理4个Cache Line。这个管理算法可以是P-LRU,当然,也可以是王大师的WLRU算法。这个SET里面的替换算法在此不讨论。基本上类似于贵族幼儿园内部的潜规则。例如,送礼多的,老师就照顾多点。或者不送礼的,下个学期突然就让你的孩子out了,被另外一个小replace你们家小孩的名额了。 我们现在来看一个OS层面的Page,4K大小。是如何落在这16384个SET里的。 不失一般性,我们假设这个Physical Page是0×0. 最低端的4K内存。 我们来考察其在这个2M Cache中的分布情况。 问题一: 一个Page有多少Cache Line? 现在假设我们对这个4K的区域做一个memset(0x0,0, 4*1024). 显然,在2M Cache的CPU下,这个4K的内存一定都会被带到Cache中来。 但是如何分布的? 是散落在这16384个SET中的某一个连续的128个SET中的。这里的某一个,其实就是第一个128个SET。 上述的这段话要绝对的理解清楚。否则下面的图都无法看,和对Page Coloring无法理解。 一个4K大小的物理内存的东西被按照每32字节大小放在了128个不同的SET中 reduced to: 4千个贪官,来自不同的机关单位。每个单位是32个人,排队去天上人间(北方干部),或者去东莞(南方干部),或者去成都(西部干部)。 妈咪是这样处理的:
【妈咪注:每一个包厢其实可以容纳4组(32×4)贪官。但另外3组席位那是为另外贪官队伍准备的。目前,就只放一组进来】 ×不同单位的干部们都在相邻的前后左右包厢里。 ×4千个贪官整了128个包厢
那么物理页面1是如何在Cache中分布的?
以此类推,第3,4,5个物理页面也都会被分配和跟在后面的Cache SET 中,而不会与前面的物理页面占据的Cache位置相冲突。 Until 第(16386/128=2^14/2^7=2^7=128)个物理页面被分配之后。 换言之,如果我们连续对128个物理页面做memset清0,就会把这个2M的L2 Cache的每个SET中放上一个Cache Line。而且没有任何冲突。
问题就是出在128个物理页面之后的事情。 事情要绕回去,从头来了。 为什么? | |
 (12个打分, 平均:4.67 / 5) (12个打分, 平均:4.67 / 5) |



Apple下的智能终端时代如何影响无线带宽(结束)
作者 manjusri | 2011-04-17 08:40 | 类型 行业动感 | 9条用户评论 »
系列目录 从终端到系统--关于无线网络的思考既有人批评标题哗众取宠,不知所云,于个人看来虽是不管大痛痒的小事,也还是从谏如流,改之。或有人称此系列为水货系列,在结束的时候,才刚刚开始无线宽带的主页,似乎就预示着未来,大希望都在管道之外或者两端,我的职业生命,还没有辉煌,就开始进入更年,但无论如何,因为cloud computing和smart terminal的迅速崛起,给渐入稳定的IP传输网络还是注入了一些新机,在这个日渐成熟的领域,任何一丝新机,都是宝贵的,决不能放过,这也是笔者之前费了那么多毫不专业的笔墨来写很不熟悉的smart terminal市场,因为这里牵动了电信供应商的主体。当然,如果我能胡诌一点云计算,估计也不会放过,只是我实在不是云里的,连胡诌都不能出来 CPU的发展史,是通过不断强悍CPU的能力,而以软件替代硬件的历史,从汉字处理、MMX、多核到APU,大体如此。所以smart terminal很容易就多核了,8核也许现在听起来似乎有点太超前了,但如果是Jobs说apple 要8核了,估计疯狂支持的多,疯狂反对的少。 什么样的应用才用得上8核,PC现在4核了,可我们都用啥了吗?要么是Wintel在骗我们的银子,要么是真的需要,可能二者兼而有之。总之,8核不是梦,也许只要5年就能看得见 从网络的角度看终端应用,就两种,一种是需要网络才能一起high的众乐乐,一种是没有别人,一个人也能high的独乐乐 个人关心的是终端/应用和带宽的关系,二者是拴在一条绳上的以用户为中心的吸血鬼。更高的终端和应用需要更高的带宽,更高的带宽也驱动更好的应用和终端开发,目前的形式看是应用终端走在了带宽前面,所以才引起了从IP RAN到IP CORE一系列的网络和产品升级,甚至移动的IPV6。 未来,移动运营如果没有固网支撑,无论从业务套餐到成本共享,都是非常不利的,所以在没有固网的移动网络,一定考虑如何收购固网运营商,当然实际操作远比这说起来复杂,vodafone也在做类似的事。 还好,这个短系列迅速的就有始有终了,而之前的城域网系列,还仍然没有什么兴趣点能让我有快感再写些什么,看来是伪江郎才尽的时候了,也许就此封笔,不再写这些没有多大实际价值的东西了,多赚点银子养老才是真正的主业。 | |
|
(1个打分, 平均:5.00 / 5) |
博鳌论坛–移动互联网
作者 陈怀临 | 2011-04-15 20:44 | 类型 行业动感 | 4条用户评论 »
性能优化的方法和技巧:代码
作者 kernelchina | 2011-04-15 01:53 | 类型 行业动感 | 27条用户评论 »
系列目录 性能优化方法和技巧代码层次的优化是最直接,也是最简单的,但前提是要对代码很熟悉,对系统很熟悉。很多事情做到后来,都是一句话:无他,但手熟尔^-^。 在展开这个话题之前,有必要先简单介绍一下Cache相关的内容,如果对这部分内容不熟悉,建议先补补课,做性能优化对Cache不了解,基本上就是盲人骑瞎马。 Cache一般来说,需要关心以下几个方面 1)Cache hierarchy Cache的层次,一般有L1, L2, L3 (L是level的意思)的cache。通常来说L1,L2是集成 在CPU里面的(可以称之为On-chip cache),而L3是放在CPU外面(可以称之为Off-chip cache)。当然这个不是绝对的,不同CPU的做法可能会不太一样。这里面应该还需要加上 register,虽然register不是cache,但是把数据放到register里面是能够提高性能的。 2)Cache size Cache的容量决定了有多少代码和数据可以放到Cache里面,有了Cache才有了竞争,才有 了替换,才有了优化的空间。如果一个程序的热点(hotspot)已经完全填充了整个Cache,那 么再从Cache角度考虑优化就是白费力气了,巧妇难为无米之炊。我们优化程序的目标是把 程序尽可能放到Cache里面,但是把程序写到能够占满整个Cache还是有一定难度的,这么大 的一个Code path,相应的代码得有多少,代码逻辑肯定是相当的复杂(基本上是不可能,至少 我没有见过)。 3)Cache line size CPU从内存load数据是一次一个cache line;往内存里面写也是一次一个cache line,所以一个 cache line里面的数据最好是读写分开,否则就会相互影响。 4)Cache associative Cache的关联。有全关联(full associative),内存可以映射到任意一个Cache line;也有N-way 关联,这个就是一个哈希表的结构,N就是冲突链的长度,超过了N,就需要替换。 5)Cache type 有I-cache(指令cache),D-cache(数据cache),TLB(MMU的cache),每一种又有L1, L2等等,有区分指令和数据的cache,也有不区分指令和数据的cache。 更多与cache相关的知识,可以参考这个链接: http://en.wikipedia.org/wiki/CPU_cache 或者是附件里面的cache.pdf,里面有一个简单的总结。 代码层次的优化,主要是从以下两个角度考虑问题: 1)I-cache相关的优化 例如精简code path,简化调用关系,减少冗余代码等等。尽量减少不必要的调用。但是有用还是无用,是和应用相关的,所以代码层次的优化很多是针对某个应用或者性能指标的优化。有针对性的优化,更容易得到可观的结果。 2)D-cache相关的优化 减少D-cache miss的数量,增加有效的数据访问的数量。这个要比I-cache优化难一些。 下面是一个代码优化技巧列表,需要不断地补充,优化和筛选。 1) Code adjacency (把相关代码放在一起),推荐指数:5颗星 把相关代码放在一起有两个涵义,一是相关的源文件要放在一起;二是相关的函数在object文件 里面,也应该是相邻的。这样,在可执行文件被加载到内存里面的时候,函数的位置也是相邻的。 相邻的函数,冲突的几率比较小。而且相关的函数放在一起,也符合模块化编程的要求:那就是 高内聚,低耦合。 如果能够把一个code path上的函数编译到一起(需要编译器支持,把相关函数编译到一起), 很显然会提高I-cache的命中率,减少冲突。但是一个系统有很多个code path,所以不可能面 面俱到。不同的性能指标,在优化的时候可能是冲突的。所以尽量做对所以case都有效的优化, 虽然做到这一点比较难。 2) Cache line alignment (cache对齐),推荐指数:4颗星 数据跨越两个cache line,就意味着两次load或者两次store。如果数据结构是cache line对齐的, 就有可能减少一次读写。数据结构的首地址cache line对齐,意味着可能有内存浪费(特别是 数组这样连续分配的数据结构),所以需要在空间和时间两方面权衡。 3) Branch prediction (分支预测),推荐指数:3颗星 代码在内存里面是顺序排列的。对于分支程序来说,如果分支语句之后的代码有更大的执行几率, 那么就可以减少跳转,一般CPU都有指令预取功能,这样可以提高指令预取命中的几率。分支预测 用的就是likely/unlikely这样的宏,一般需要编译器的支持,这样做是静态的分支预测。现在也有 很多CPU支持在CPU内部保存执行过的分支指令的结果(分支指令的cache),所以静态的分支预测 就没有太多的意义。如果分支是有意义的,那么说明任何分支都会执行到,所以在特定情况下,静态 分支预测的结果并没有多好,而且likely/unlikely对代码有很大的侵害(影响可读性),所以一般不 推荐使用这个方法。 4) Data prefetch (数据预取),推荐指数:4颗星 指令预取是CPU自动完成的,但是数据预取就是一个有技术含量的工作。数据预取的依据是预取的数据 马上会用到,这个应该符合空间局部性(spatial locality),但是如何知道预取的数据会被用到,这个 要看上下文的关系。一般来说,数据预取在循环里面用的比较多,因为循环是最符合空间局部性的代码。 但是数据预取的代码本身对程序是有侵害的(影响美观和可读性),而且优化效果不一定很明显(命中 的概率)。数据预取可以填充流水线,避免访问内存的等待,还是有一定的好处的。 5) Memory coloring (内存着色),推荐指数:不推荐 内存着色属于系统层次的优化,在代码优化阶段去考虑内存着色,有点太晚了。所以这个话题可以放到 系统层次优化里面去讨论。 6)Register parameters (寄存器参数),推荐指数:4颗星 寄存器做为速度最快的内存单元,不好好利用实在是浪费。但是,怎么用?一般来说,函数调用的参数 少于某个数,比如3,参数是通过寄存器传递的(这个要看ABI的约定)。所以,写函数的时候,不要 带那么多参数。c语言里还有一个register关键词,不过通常都没什么用处(没试过,不知道效果,不过 可以反汇编看看具体的指令,估计是和编译器相关)。尝试从寄存器里面读取数据,而不是内存。 7) Lazy computation (延迟计算),推荐指数:5颗星 延迟计算的意思是最近用不上的变量,就不要去初始化。通常来说,在函数开始就会初始化很多数据,但是 这些数据在函数执行过程中并没有用到(比如一个分支判断,就退出了函数),那么这些动作就是浪费了。 变量初始化是一个好的编程习惯,但是在性能优化的时候,有可能就是一个多余的动作,需要综合考虑函数 的各个分支,做出决定。 延迟计算也可以是系统层次的优化,比如COW(copy-on-write)就是在fork子进程的时候,并没有复制父 进程所有的页表,而是只复制指令部分。当有写发生的时候,再复制数据部分,这样可以避免不必要的复制, 提供进程创建的速度。 8] Early computation (提前计算),推荐指数:5颗星 有些变量,需要计算一次,多次使用的时候。最好是提前计算一下,保存结果,以后再引用,避免每次都 重新计算一次。函数多了,有时就会忽略这个函数都做了些什么,写程序的人可以不了解,但是优化的时候 不能不了解。能使用常数的地方,尽量使用常数,加减乘除都会消耗CPU的指令,不可不查。 9)Inline or not inline (inline函数),推荐指数:5颗星 Inline or not inline,这是个问题。Inline可以减少函数调用的开销(入栈,出栈的操作),但是inline也 有可能造成大量的重复代码,使得代码的体积变大。Inline对debug也有坏处(汇编和语言对不上)。所以 用这个的时候要谨慎。小的函数(小于10行),可以尝试用inline;调用次数多的或者很长的函数,尽量不 要用inline。 10) Macro or not macro (宏定义或者宏函数),推荐指数:5颗星 Macro和inline带来的好处,坏处是一样的。但我的感觉是,可以用宏定义,不要用宏函数。用宏写函数, 会有很多潜在的危险。宏要简单,精炼,最好是不要用。中看不中用。 11) Allocation on stack (局部变量),推荐指数:5颗星 如果每次都要在栈上分配一个1K大小的变量,这个代价是不是太大了哪?如果这个变量还需要初始化(因 为值是随机的),那是不是更浪费了。全局变量好的一点是不需要反复的重建,销毁;而局部变量就有这个 坏处。所以避免在栈上使用数组等变量。 12) Multiple conditions (多个条件的判断语句),推荐指数:3颗星 多个条件判断时,是一个逐步缩小范围的过程。条件的先后,决定了前面的判断是否多余的。根据code path 的情况和条件分支的几率,调整条件的顺序,可以在一定程度上减少code path的开销。但是这个工作做 起来有点难度,所以通常不推荐使用。 13) Per-cpu data structure (非共享的数据结构),推荐指数:5颗星 Per-cpu data structure 在多核,多CPU或者多线程编程里面一个通用的技巧。使用Per-cpu data structure的目的是避免共享变量的锁,使得每个CPU可以独立访问数据而与其他CPU无关。坏处是会 消耗大量的内存,而且并不是所有的变量都可以per-cpu化。并行是多核编程追求的目标,而串行化 是多核编程里面最大的伤害。有关并行和串行的话题,在系统层次优化里面还会提到。 局部变量肯定是thread local的,所以在多核编程里面,局部变量反而更有好处。 14) 64 bits counter in 32 bits environment (32位环境里的64位counter),推荐指数:5颗星 32位环境里面用64位counter很显然会影响性能,所以除非必要,最好别用。有关counter的优化可以多 说几句。counter是必须的,但是还需要慎重的选择,避免重复的计数。关键路径上的counter可以使用 per-cpu counter,非关键路径(exception path)就可以省一点内存。 15) Reduce call path or call trace (减少函数调用的层次),推荐指数:4颗星 函数越多,有用的事情做的就越少(函数的入栈,出栈等)。所以要减少函数的调用层次。但是不应该 破坏程序的美观和可读性。个人认为好程序的首要标准就是美观和可读性。不好看的程序读起来影响心 情。所以需要权衡利弊,不能一个程序就一个函数。 16) Move exception path out (把exception处理放到另一个函数里面),推荐指数:5颗星 把exception path和critical path放到一起(代码混合在一起),就会影响critical path的cache性能。 而很多时候,exception path都是长篇大论,有点喧宾夺主的感觉。如果能把critical path和 exception path完全分离开,这样对i-cache有很大帮助。 17) Read, write split (读写分离),推荐指数:5颗星 在cache.pdf里面提到了伪共享(false sharing),就是说两个无关的变量,一个读,一个写,而这 两个变量在一个cache line里面。那么写会导致cache line失效(通常是在多核编程里面,两个变量 在不同的core上引用)。读写分离是一个很难运用的技巧,特别是在code很复杂的情况下。需要 不断地调试,是个力气活(如果有工具帮助会好一点,比如cache miss时触发cpu的execption处理 之类的)。 18) Reduce duplicated code(减少冗余代码),推荐指数:5颗星 代码里面的冗余代码和死代码(dead code)很多。减少冗余代码就是减小浪费。但冗余代码有时 又是必不可少(copy-paste太多,尾大不掉,不好改了),但是对critical path,花一些功夫还 是必要的。 19) Use compiler optimization options (使用编译器的优化选项),推荐指数:4颗星 使用编译器选项来优化代码,这个应该从一开始就进行。写编译器的人更懂CPU,所以可以放心 地使用。编译器优化有不同的目标,有优化空间的,有优化时间的,看需求使用。 20) Know your code path (了解所有的执行路径,并优化关键路径),推荐指数:5颗星 代码的执行路径和静态代码不同,它是一个动态的执行过程,不同的输入,走过的路径不同。 我们应该能区分出主要路径和次要路径,关注和优化主要路径。要了解执行路径的执行流程, 有多少个锁,多少个原子操作,有多少同步消息,有多少内存拷贝等等。这是性能优化里面 必不可少,也是唯一正确的途径,优化的过程,也是学习,整理知识的过程,虽然有时很无聊, 但有时也很有趣。 代码优化有时与编程规则是冲突的,比如直接访问成员变量,还是通过接口来访问。编程规则上肯定是说要通过接口来访问,但直接访问效率更高。还有就是许多ASSERT之类的代码,加的多了,也影响性能,但是不加又会给debug带来麻烦。所以需要权衡。代码层次的优化是基本功课,但是指望代码层次的优化来解决所有问题,无疑是缘木求鱼。从系统层次和算法层次考虑问题,可能效果会更好。 代码层次的优化需要相关工具的配合,没有工具,将会事倍功半。所以在优化之前,先把工具准备好。有关工具的话题,会在另一篇文章里面讲。 还有什么,需要好好想想。这些优化技巧都是与c语言相关的。对于其他语言不一定适用。每个语言都有一些与性能相关的编码规范和约定俗成,遵守就可以了。有很多Effective, Exceptional 系列的书籍,可以看看。 代码相关的优化,着力点还是在代码上,多看,多想,就会有收获。 参考资料: 1)http://en.wikipedia.org/wiki/CPU_cache 2) Effective C++: 55 Specific Ways to Improve Your Programs and Designs (3rd Edition) 3) More Effective C++: 35 New Ways to Improve Your Programs and Designs 4) Effective STL: 50 Specific Ways to Improve Your Use of the Standard Template Library | |
|
(4个打分, 平均:4.75 / 5) |
从apple 8核到无线带宽 – 谁的未来不是梦?
作者 manjusri | 2011-04-14 21:33 | 类型 行业动感 | 10条用户评论 »
系列目录 从终端到系统--关于无线网络的思考从谏如流呀,因有少儿不宜部分,此文删去若干□□□□ 微软是个人偏见里最不喜欢的一个帝国。 闲话扯远了了,回归正题,PC在诞生之初,apple有和现在iphone/pad类似的情形,Wintel在PC大胜apple的历史,也是apple因为不能速胜而被Wintel的PC同一化和大众化的持久战打败的例子,jobs回归后创造的新的apple,能否因其新的app产业链而避免覆辙?很难,apple的文化和生存基因是创新,不是大众化的产品,而smart terminal沦为大众化和同一化是IT时代摩尔定律下不可避免的,apple的长期生存在于其能否持续的通过创新拉开对手,一旦在一定时期内做不到这一代点,apple就会面临生存的危机,jobs回归前apple的囧境,不就是回首可望的鲜活案例吗?如果只看当下,不回头研究历史和远瞻前路,就不会有历史大势和未来大势的判断和感觉。希望apple创造一个新的帝国,火星正在撞地球,但我希望的是最后火星和地球共处,而微软灭亡 产业链的模式比较: Android是全开放的现代派自由主义,全开放甚至全裸上镜,还可由人DIY。因为各种方式复杂,自然也有人觉得体验不稳定不爽。Google又图的是什么呢?当然不是完全免费的午餐,也不是收费的OS,Google图的是统一了终端的OS后,可以把Google能提供的所有业务都内置进去,虽然允许定制,但还是能有很多应用被直接使用,android的用户越多,意味着Google的业务的用户就越多,用户数量意味着什么再清楚不过了,有了用户,你几乎可以做任何事,这是目前互联网所有业务的基础,用户基数是所有互联网公司成功的基础,任何一个internet应用,衡量它能否成功的第一个标准不是立即盈利,而是能否粘住一个用户基数,有了这个,才能谈后面如何盈利,最简单的就是广告,然后就是电子商务(C2C/B2C/团购),而没有这个,一切盈利都是空中楼阁,未来的竞争就是对用户基数的竞争,各路英雄拼尽最后一滴血要得到的,就是谁能垄断用户的心。 WM本质还是老式做派,半收半开,靠body赚辛苦钱,为了生存,刚刚倒贴勾了一个老大款。犹如华为还是没有找到开启美国大门的通用钥匙,微软也仍然没有明白如何获得internet用户的心,微软做老大太久了,改不过来了。 PC时代的Wintel,mobile时代是GoogleARM?Wintel没能续写PC霸业到mobile,是否已经说Wintel不能适应Jobs开启的smart mobile时代?那么GoogleARM的开放模式能在mobile时代完成Wintel在PC时代的霸业吗?还是apple惨败于PC后在mobile终于修成大业? 历史战绩上,开放的Wintel战胜了封闭的apple,也战胜了自由的Linux,但那都代表历史,新的时代大戏,主角由apple/Google领衔,但是谁能笑到最后? 喜欢技术细节和startup的,smart terminal提供了很多新的机会,Smart terminal好日子才开始,还有许多问题意味着所有参与者的机会。CPU不会是问题,无论是多核还是APU,但还有很多很好的主题,比如 我相信Jobs Apple是一个正在进行时的神话,但不要长期迷信在神话中,你有你的自我,不是jobs,也不是apple,就是你自己 下一章:Apple下的智能终端时代如何影响无线带宽(结束) | |
|
(6个打分, 平均:1.83 / 5) |
现代 CPU 中的 Cache 结构
作者 comcat | 2011-04-14 20:07 | 类型 专题分析 | 26条用户评论 »
|
0.缘起 受首席启发,补充点 cache 背景。再乱弹一下 Page Coloring
1. 概述 Cache 是用来对内存数据的缓存。CPU 要访问的数据在Cache中有缓存,称为“命中” (Hit),反之则称为“缺失” (Miss) CPU 访问它的速度介于寄存器与内存之间(数量级的差别)。实现 Cache 的花费介于寄存器与内存之间。 现在 CPU 的 Cache 又被细分了几层,常见的有 L1 Cache, L2 Cache, L3 Cache,其读写延迟依次增加,实现的成 现代系统采用从 Register —> L1 Cache —> L2 Cache —> L3 Cache —> Memory —> Mass storage 引入 Cache 的理论基础是程序局部性原理,包括时间局部性和空间局部性。即最近被CPU访问的数据,短期内 CPU
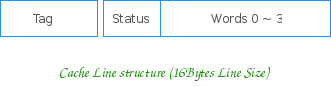
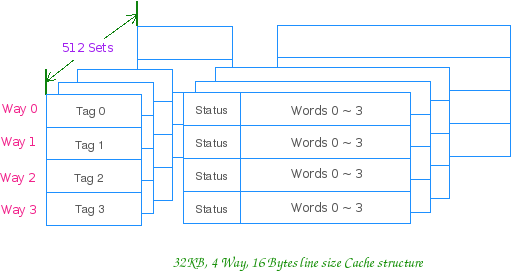
2. 结构 2.1 Cache 行 Cache 以行大小(Line size)为单位分成若干个行。行 (Line) 是 Cache 的数据存储和管理单元。一个典型的 Cache 行
其由 Tag 域、Status 域和数据域组成, Tag 域存放该行数据对应地址的高位。CPU 在索引后,用相应地址与组内所有行的 Tag 相比较,以之区分具体的行。 数据域能容纳的字节数是为行大小 (Line Size),其为 Cache 与内存之间数据交换的单位。 Status 域则为一些控制位信息(如Valid, Lock 以及Parity check 位等等),不同的Cache 类型,不同的 Cache 实
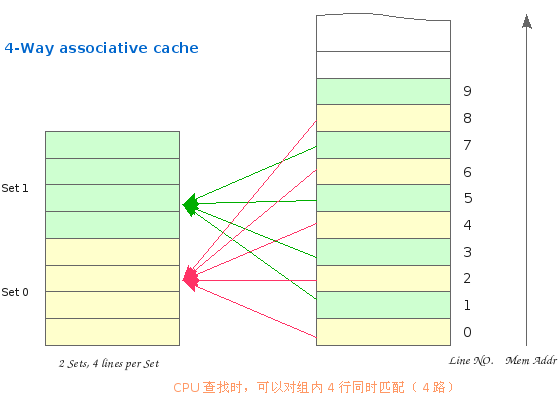
2.2 相联方式 2.2.1 组相联 通俗地讲就是 Cache 行的分组,比如 4 路组相联,就是 4 行一组,4 行一组。。。。。。 比如 32KB 的 4 路组相联 Cache,行大小为 16Bytes 的话,他就有 32*1024/(16 * 4)= 512 组 CPU 访问组相联 Cache 时,就先用地址索引到组,然后组内同时匹配 Tag,进行路选。一个典型的组相联 Cache
内存逻辑上也按 Cache 行大小分块,按地址由低向高,依次编号。因此 Cache 与内存就会有个映射问题,如:第四 组相联的 Cache 是先索引组,其规则为: Cache 组号 = 内存行号 % Cache 总组数
对于上图这个只有 2 个组的 Cache,假设其行大小为 16Bytes,这个组索引的过程,实际上就是用地址的第 5 位 尔后,内存行可以映射到该组内的任意行上。缓存数据时,有空占空,如组内所有行被占用,则使用替换算法(LRU,
2.2.2 直接相联 略. 或可参阅 The MIPS Cache Architecture 的相关部分
2.2.3 全相联 略. 或可参阅 The MIPS Cache Architecture 的相关部分
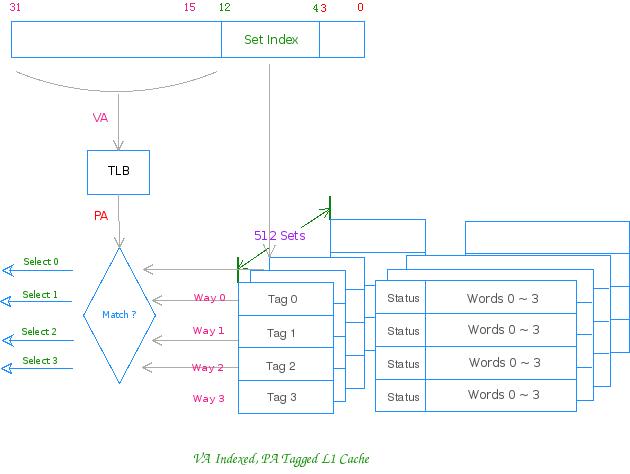
3. 组相联工作方式 K 路组相联 Cache 的通常工作方式是:先用物理地址或虚拟地址索引组,然后用物理地址 (PA) 或虚拟地址 (VA) 同 以上述 32KB ,4 路组相联,行大小为 16Bytes 的 Cache 为例,正常工作时其对地址的划分如下所示:
Addr[12:4] 用来索引组,9 bit 可索引 512 组 VA 索引,PA 匹配 Cache 之工作方式图:
4. 乱弹 在 OS 层面上,我们还有分页的概念,物理内存被分为若干个 Page Frame,其大小以 4KB 始。对 4KB 页大小的系 若系统采用 4KB 的 PAGE_SIZE,则第一个 Page Frame 总是会被索引到 cache 的前 256 组,第二个 Page Frame 通俗地说,就是让 OS 在分配页面的时候,让红色的页和黑色的页一样多。这个应该就是 Page Coloring,不知道对不 用颜色位更形式化地说: 作为一个理解的便利,请各位看官看看地址的组索引位和行内索引位所表示的空间大小是多少? 2^13 = 8KB,这个 因此拿到一个 Cache 在判断系统的 Color 位时,可以借助一个 Way Array 的概念,一路 Cache 的大小就是地址用 当 Way_Size > PAGE_SIZE 时,即 log2(Way_Size) > log2(PAGE_SIZE), 则用于索引一路 Cache 的地址低位较 若 log2(Way_Size) <= log2(PAGE_SIZE),则数据可以很均衡地进入 Cache 没有谈论的必要的,但可以作为另外一
5. 摘要 Way_Size = Cache_Size / Ways 当 log2(Way_Size) > log2(PAGE_SIZE) 时,系统具有“颜色位”,其影响为: 1. 用 VA 索引,PA 匹配的 Cache,会存在 Cache alias 问题 个人觉得在可能的前提下,提高 PAGE SIZE 比较靠谱,大页的影响,除了在 Cache 上外,在 RISC 的 CPU 上,还
| |
|
(12个打分, 平均:5.00 / 5) |

中国2010年SSL VPN市场概况
作者 xiudong | 2011-04-14 19:40 | 类型 行业动感 | 19条用户评论 »
|
由于报告属于分析公司资源,不能随意公开发布,只能引用,我这就只有先将小弟的部分解释发出来了:)
2010年,深信服科技以36.4%的市场占有率再次领先于其余厂商,且相对于2008年的31.1%、2009年的34%一直保持着良好的增长。报告显示,深信服SSL VPN在2010年实现了强劲的市场增长,分析师认为快速增长的渠道网络帮助深信服为最为广泛的中国用户提供了服务。此外,深信服科技在中国SSL VPN细分市场不断提升的高知名度以及对高端用户提供的持续关注支持确保了深信服在SSL VPN市场的客户粘性和足够的牵引力。 | |
|
(3个打分, 平均:3.33 / 5) |
