




Google在建设自己的IP核心网吗?
作者 高飞 | 2011-07-24 07:20 | 类型 下一代互联网, 专题分析, 云计算, 互联网 | 9条用户评论 »
系列目录 The Google Internet
若干年以来,坊间一直就传说Google在游走于“成为ISP或者运营商”的边缘。Google是White Space计划的重要推手(即转换未使用的电视频段用于宽带网);几年前Google据传一直在整合dark fiber,并在雇佣人员来商谈城区和远程dark fiber的合同;Google目前也在总部所在的加州山景城及周郊运营一个免费的WiFi网络。 2010年Google曾宣布公司要在全美一些地区建设和测试超高速宽带网,光纤1G入户。对于Google遍及全球各地的数据中心,Google一直在建设高速网络更快捷的内联和互联,坊间流传选择的是Juniper T系列路由器和TX来搭IP核心网。 已经披露的报道表明,Google的具体use case包括:更佳的用户体验(搜索和各种应用响应的速度和相关性),高速条件下可能出现的下一代网络应用,新的网络部署技术,网络的开放性和选择性。Google自建网络的定位大概是网络批发商,而不是直接面向消费者。这个准运营商/ISP的地位也会有助于Google的主营业务—比如Google Voice挑战Skype/微软,Chrome OS上网本集成利用Google的这些基础设施,Google+从其中找到killer App,云云。 笔者有意搜集一些资料分析一下Google自建的这个IP核心网,包括数据中心、节点分布、互联状况、设备、自治系统、策略等等。弯友们如果手边有这样的资料,大力欢迎与笔者共享相关信息,只要不泄密和惹来麻烦…………反正最后都出现在文章里。 笔者联系办法gaofei@valleytalk.org | |
 (2个打分, 平均:5.00 / 5) (2个打分, 平均:5.00 / 5) |
OpenFlow技术及应用模式发展分析
作者 老韩 | 2011-05-21 10:34 | 类型 互联网, 弯曲推荐, 新兴技术 | 88条用户评论 »
|
近来OpenFlow的话题比较多,INFOCOM上清华土著又给上了一课,就找了些资料学习了一下,顺带编写了这篇科普文章。感谢许多朋友在撰写过程中的帮助和启发,另外yeasy兄发在弯曲的系列文章也非常有价值。很喜欢LiveSec团队的开放心态,希望能帮他们的产品和理念做尽量广泛的传播。 原文发于《计算机世界》。顺带说下,最近要做NFGW的选题了,感兴趣的朋友来找我吧,Email和GTalk是hanxu0514 aT gmail dOt com。
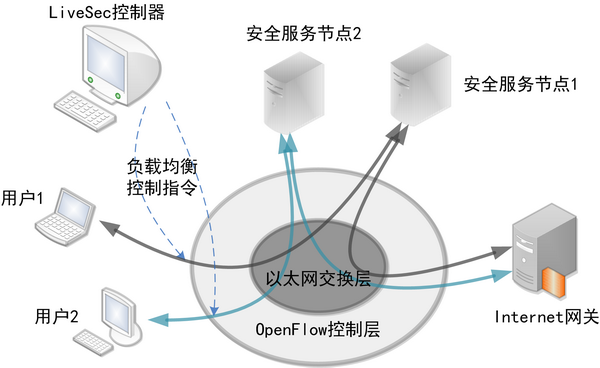
4月10日至15日,第30届IEEE计算机通信国际大会 (INFOCOM 2011)在上海国际会议中心隆重举行。本次会议吸引了国内外1000多名计算机和通信领域的专家、学者和企业的科研人员到场,重点围绕云计算、网络安全、数据中心网络、移动互联网、物联网等一系列研究领域的前沿问题进行了深入的探讨。在倍受关注的现场展示环节中(Live Demo),来自清华大学信息技术研究院网络安全实验室的师生们展示了基于OpenFlow的网络安全管理系统LiveSec,引起了与会者的普遍关注。该系统的成功运行,是国内通信领域的研发团队对前沿技术跟踪、创新工作的完美诠释,在科研成果转化为可用产品的道路上占据了先机。 OpenFlow扬帆起航 OpenFlow技术最早由斯坦福大学提出,旨在基于现有TCP/IP技术条件,以创新的网络互联理念解决当前网络面对新业务产生的种种瓶颈,已被享有声望的《麻省理工科技评论》杂志评为十大未来技术。它的核心思想很简单,就是将原本完全由交换机/路由器控制的数据包转发过程,转化为由OpenFlow交换机(OpenFlow Switch)和控制服务器(Controller)分别完成的独立过程。转变背后进行的实际上是控制权的更迭:传统网络中数据包的流向是人为指定的,虽然交换机、路由器拥有控制权,却没有数据流的概念,只进行数据包级别的交换;而在OpenFlow网络中,统一的控制服务器取代路由,决定了所有数据包在网络中传输路径。OpenFlow交换机会在本地维护一个与转发表不同的流表(Flow Table),如果要转发的数据包在流表中有对应项,则直接进行快速转发;若流表中没有此项,数据包就会被发送到控制服务器进行传输路径的确认,再根据下发结果进行转发。 OpenFlow网络的这个处理流程,有点类似于状态检测防火墙中的快速路径与慢速路径的处理,只不过转发与控制层面在物理上完全分离。这也意味着,OpenFlow网络中的设备能够分布部署、集中管控,使网络变为软件可定义的形态。在OpenFlow网络中部署一种新的路由协议或安全算法,往往仅需要在控制服务器上撰写数百行代码。加州大学伯克利分校的Scott Shenker教授对此有着很到位的评价:“OpenFlow并不能让你做你以前在网络上不能做的一切事情,但它提供了一个可编程的接口,让你决定如何路由数据包、如何实现负载均衡或是如何进行访问控制。因此,它的这种通用性确实会促进发展。” 在得到学术界的普遍认可后,工业界也开始对这项新技术表达出浓厚的兴趣。OpenFlow已经在美国斯坦福大学、Internet2、日本的JGN2plus等多个科研机构中得到部署,网络设备生产商思科、惠普、Juniper、NEC等巨头也纷纷推出了支持OpenFlow的有线和无线交换设备,而谷歌、思杰等网络应用和业务厂商则已将OpenFlow技术用于其不同的产品中。就在半个月前,以OpenFlow为产品核心设计理念的初创企业Big Switch Networks成功完成了总额1375万美元的第一轮融资,标志着资本市场对这项新技术及其发展前景的充分认可。目前,OpenFlow的推广组织开放网络基金会(Open Networking Foundation)的成员基本涵盖了所有网络及互联网领域的巨头。 好用才是硬道理 使用新技术的代价往往十分高昂,好在OpenFlow具有足够的开放性,给在传统网络中的融合实现带来可能。清华大学信息技术研究院网络安全实验室在本届INFOCOM大会上现场展示的部署在清华大学信息楼内的LiveSec网络安全系统,就是一个非常好的范本。该系统在传统的以太网之上,通过无线接入技术和虚拟化技术引入了基于OpenFlow协议的控制层,显著降低了构建成本。
LiveSec网络安全系统包含三层架构:
基于上述架构,LiveSec相对传统的安全部署模型具有多重优势。首先,该系统解决了安全设备的可扩展问题。通过全局细粒度的负载均衡,LiveSec支持安全设备在网络的任意位置进行增量式部署。新部署的节点会按照OpenFlow协议自行入网,并自动将控制权交由LiveSec控制器。所有的用户和服务节点均可在LiveSec网络内动态迁移,包括无线接入和虚拟机的无缝迁移。记者在展示现场尝试进行了基于虚拟机的服务节点动态加入网络的实验,当具有安全检测能力的虚拟机加入网络中时,LiveSec的可视化界面会显示出该虚拟机在网络中的拓扑及其具备的业务能力(如杀毒功能,协议识别功能等)。LiveSec控制器会依据新增节点的处理能力将需要安全处理的网络流量均衡到新的节点上,从可视化界面中也可以看到新增节点引起的链路流量变化。
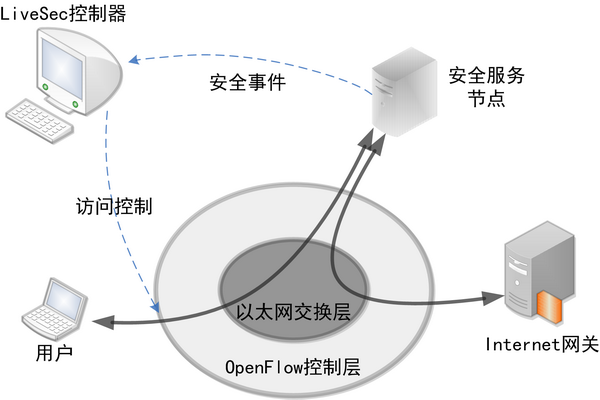
传统网络中,安全设备一般被部署在边缘,对进出流量进行访问控制。这种方式虽然成熟有效,对内网中的安全问题却无能为力。LiveSec创新的交互式访问控制特性则能很好地解决这一难题,由于系统提供了安全节点到控制器的信息交换通路,并针对安全事件设计了一套信息交换协议,LiveSec可以根据安全节点传来的安全事件,在用户接入层实施访问控制。这意味着,该系统做到了全网的点到点安全控制,任何攻击流量在不离开接入交换机的情况下就被扼杀在萌芽状态,内网安全的顽疾可以从根本上得到解决。
在OpenFlow网络中,控制服务器管控着所有的数据流,又能实时感知其他节点的状态,为可视化提供了足够的基础。记者在展示中看到,LiveSec结合OpenFlow协议以及应用层业务识别服务节点,将网络中所有的拓扑、流量、应用、安全变化都按照统一格式写入中央数据库,并在动态界面中实现了包括当前状态及历史事件回放在内的全网业务可视化。当使用无线设备的用户通过OpenFlow无线路由器接入后,立即会显示在系统的可视化界面中。该用户上网所涉及的应用层协议,也会实时显示在用户图标一侧。当用户访问不良网站或者进行攻击时,图标上会出现红色警示,LiveSec也会依据安全策略在用户接入端实时阻止用户的部分或所有流量。历史回放功能也相当实用,可以回放特定时间段内LiveSec的所有事件,攻击发起者包括地理位置在内的所有信息均可以通过数据库查找获取。 图4. 在清华大学信息楼部署的LiveSec系统 商业模式定成败 虽然OpenFlow网络从根本上解决了传统网络存在的很多问题,却也因标准化过程刚刚起步,缺乏大众化的、实用的落地方案,至今仍然多被用于各类实验性质的网络。在其发展的道路上,势必还要经历扩大用户规模和商业模式创新两大阶段。而纵观近年来IT行业巨头们的发展情况,缔造一个成功的商业模式,其重要性显然远远超过了技术创新。
未来的数据中心网络越来越趋向于由虚拟机和服务器群所组成,数据中心的交换架构则趋向扁平,使用高性能交换机群组或clos 网络甚至可以支持百万个节点的无阻塞互联。在这种情况下,网络服务质量及高可用性成为用户最为关心的问题。以LiveSec为代表的基于OpenFlow的网络操作系统支持网络设备的分布式部署,有效避免了单点失效问题。控制服务器的分布式部署,则可以利用分布式哈希技术同步全网拓扑和策略。当网络出现局部故障时,系统可以利用OpenFlow协议迅速构建全新的互联拓扑,甚至可以为不同的业务和应用分别构建不同的拓扑,以满足安全和服务质量的需求。这又是新的商业机会,试想一下,在OpenFlow网络的支持下,IaaS提供商可以为用户交付一个独一无二的网络,用户甚至可以自行设定数据流在本网内的路径和安全策略,而不仅仅是几个虚拟设备的控制权。 从系统实现模式的角度看,LiveSec的模式是构建网络操作系统(基于开源项目Nox),这个发展方向已经被许多业内人士所认同。不管对象是桌面还是网络,操作系统存在的根本意义都是管理设备和提供编程接口。众所周知,想发挥一块高性能显卡的处理能力,必须先安装该硬件的驱动。基于OpenFlow的网络操作系统也是如此,仍以LiveSec为例,所有OpenFlow交换设备和安全服务节点都可看作网络系统中的硬件设备,安全业务的实现则通过服务节点上的软件完成。当新的服务节点加入网络时,LiveSec控制器首先要知道这个节点能处理什么业务,以及如何与设备建立通信机制,才能让安全处理的执行者和决策者有效地互动起来。出于商业层面的考虑,这种机制的建立往往由服务提供者主动告知控制器,需要一个与电脑安装硬件驱动十分相似的过程。对网络管理者来说,这个步骤简化了部署及使用难度;而对设备制造商而言,这种方式也有利于将现有针对传统网络的产品快速移植到OpenFlow网络中。 受当前流行的运营模式影响,基于OpenFlow的网络操作系统也在加入更多的应用发行元素。当用户在控制台中添加服务如同在App Store获取应用般便捷时,OpenFlow网络的建设必然会步入高速发展阶段。实际上,这种发行模式与当前许多云安全服务的商务模式是可以无缝对接的,为云安全的落地提供了绝佳的渠道。以抗DDoS需求为例,在用户购买对象大量地由专用设备转向清洗服务的今天,供应商可以通过系统内置的发行体系为用户提供自助服务,然后按次数或处理能力收取费用;用户完全不必考虑现实中令人头疼的部署问题,只需通过“软件商店”下载安装相应服务,就能为OpenFlow网络添加抗DDoS的能力。
| |
 (8个打分, 平均:4.38 / 5) (8个打分, 平均:4.38 / 5) |




从互联网云计算平台看数据中心接入层网络隔离设计
作者 zhihuayang | 2011-05-16 07:41 | 类型 云计算, 互联网, 网络安全 | 90条用户评论 »
|
1、何为云计算平台 说到云计算平台,不得不提开放平台。去年以来,开放平台这个字眼可谓是炙手可热。自Facebook、Apple将开放平台的成功演绎至极致,中国互联网界便掀起了一股“开放潮”,新浪、百度、淘宝、360、人人、腾讯等互联网巨头,甚至是当当和京东等电子商务巨头,都放言“逐鹿”开放平台。 开放平台有三层含义:
无疑,这三者中,云计算平台才能真正解决第三方开发者面临海量用户的诸多挑战,对第三方开发者有着莫大的吸引力,可以实现互联网巨头们寡头经济和长尾经济两手硬的如意算盘,被视为未来互联网的制胜利器。因此,各互联网巨头也不惜投入巨资建设云计算平台争夺市场。据互联网公开的资料,腾讯的云计算平台opensns.qq.com开始建设仅4个月就取得出人意料的收获:
2、VLAN和IP规划面临挑战 那么,和原有仅支撑内部应用的数据中心相比,云计算平台的数据中心会面临什么样的新挑战? 显然,由于云计算平台的核心是诸多第三方应用的托管,业务隔离是首当其冲的要解决问题,否则无法确保第三方应用及数据的安全性。 从网络的角度,业务隔离必须要从接入层能够将各业务的服务器分开。网络大师们不暇思索的给出了解决方案:VLAN。 不料,问题马上来了。VLAN的规模如何确定,IP网络划分按照什么粒度进行? 云计算平台是典型的长尾经济商业模式,这也就意味着托管的应用数量庞大,大部分应用的规模较小,但谁也无法预知一觉醒来哪个应用的用户数量会暴涨,因此计算资源的伸缩性要求很大。 如果VLAN和IP网络的粒度较粗,由于大部分应用规模较小,这会带来IP地址等资源的巨大浪费。 如果VLAN和IP网络的粒度较细,意味着当应用长大时会分割在不同的VLAN和网络中,如果涉及HA、虚机迁移等特殊需求还可能需要将业务进行跨VLAN和网络的整合和迁移,这会招致业务部门的不满。更糟糕的是,服务器虚拟化技术发展很快,当服务器虚拟化1:4的时候,意味着网络设备硬件端口规模不变的情况下网络容量变成原来的4倍,如果服务器虚拟化在1:4的基础上进一步变成1:10网络容量就会猛增为最初的10倍,很轻易就会击穿VLAN和IP网络的规划,应用也将被迫进行的跨VLAN和IP网络的迁移,应用的中断将不可避免。 可是VLAN和IP网络的粒度放大到什么程度才合适那?似乎暂时没有答案。长尾应用和服务器虚拟化的发展很难准确预知。 网络大师们总是追求完美的,希望应用尽可能避免迁移,于是,另一个方案出台了。 网络大师们现在不划分细颗粒的VLAN和IP网络了,干脆创建一个大VLAN,应用的隔离通过PVLAN进行,这样IP网络的划分问题也迎刃而解了。似乎一切都完美了。 还没等网络大师们喘上两口气,就发现这个方案似乎也行不通。 首先,从技术角度,单个VLAN的规模是有限制的,由于大量生成树节点的计算会对作为根节点的三层设备的CPU产生冲击,通常一个二层网络难以超过2000台服务器(包括虚拟机)的规模。这样规模的网络对云计算平台来说太小,需要建设多个网络模块,整个数据中心的网络结构的层次要增加,跨模块的网络性能又成为另外一个浮起的瓢。 其次,在服务器虚拟化的环境下,由于目前交换机还无法直接通过端口区分虚拟机,如果想使用PVLAN隔离虚拟机,服务器虚拟化平台就必须支持PVLAN TRUNK,或者说母机内置的虚拟交换机必须支持PVLAN TRUNK。目前业界仅Cisco的Nexus1000v可以支持,但限于vmware平台,而更受互联网行业青睐的开源解决方案尚无踪影。 前一个问题,即将出台的IETF的Trill标准,或者现在业界已有的解决方案,如Cisco的Fabric Path,可以在某种程度上解决,但后一个问题,网络大师们就无解了。 正当网络大师们行将崩溃的时候,一根救命稻草飘然而至,那就是即将发布的IEEE的802.1Qbg、Qbh标准。不管Qbg和Qbh双方如何争相表明己方的优势,事实上两者的最终目标是一致的,那就是要在接入交换机上通过虚拟端口的方式提供虚拟机在网络端口层面上的感知。 于是,当Qbg和Qbh商用后,接入层交换机就可以使用PVLAN的手段进行业务隔离,不管是物理机还是虚拟机。 然而事情还没结束,Qbg和Qbh并不是原有的交换机和服务器网卡所能支持的。交换机可以在建设数据中心时适当超前选择hardware ready的设备,当标准出来软件升级即可,甚至可以在原有数据中心更换接入层交换机。可是服务器的网卡选择并不是由网络大师们确定的,互联网企业定制的服务器要更换新型网卡也不是那么容易,更何况现存的大量服务器更换网卡几乎不太可能。最重要的一点,目前没有任何网络设备厂商承诺Qbg和Qbh会有PVLAN的特性支持,也许他们目前的重点是确保能够成为标准之一,还顾不上这样的细节。 终于,网络大师两眼一黑,昏倒在地。
3、VLAN+ACL卷土重来 网络大师被速效救心丸救醒,因为云计算平台正在建设中,网络规划不可缺少。 吸取了之前的经验和教训,网络大师们决定暂时抛开那些尚未发布的标准,立足于目前可用的技术。 于是,VLAN和IP网络划分又开始了,这次网络大师们仍然决定做一个尽可能大的二层网络,所不同的是,不再考虑PVLAN的隔离方式,而采用VLAN ACL的方式进行访问控制实现隔离,虚拟机的母机和接入层交换机采用vlan trunk的方式连接。这样现有的交换机和虚拟化平台都可以支持,唯一需要新增加的,就是ACL管理的工具系统,这对于研发能力超强的互联网企业,算是小菜一碟了。 还有一个对于网络大师们是好消息的事情是,业界有些网络设备厂商已经开始支持基于标签的访问控制,比如Cisco的TrustSec,可以将访问控制的矩阵规模极大的缩小,虽然需要新的网络设备型号才能完全支持,但至少事情已经在网络大师们可控制的范围内了。 网络大师们兴冲冲的带着最新的方案去和业务部门研讨,希望得到业务部门的支持,赶紧把ACL管理系统开发出来。 业务部门的一席话差点又让网络大师眼前一黑:“我们现在在服务器上用IPTables和Ptables做业务隔离,如果性能会不够,再考虑别的方式”。 | |
|
(4个打分, 平均:5.00 / 5) |
雷军 。互联网创业的葵花宝典
作者 陈怀临 | 2011-03-18 19:52 | 类型 互联网, 行业动感 | 11条用户评论 »
|
【陈怀临注:今天因为某些原因,与雷军有个电话交流。非常佩服其深邃的见解和谦卑的人品。也得知了其博客文章。其原文和网站为 www.leijun.com。希望同学们多多阅读。非常有帮助。】 一个朋友,在一家软件的大企业做了十年的软件研发,想出来创业,问我要注意什么。我开玩笑说,要想成功,必须学习互联网创业的“葵花宝典”,第一条就是 “挥刀自宫”。 大的软件公司有很多资源,研发能力不错,各种推广资源也非常优越,但很少开发出来优秀的互联网产品。初步看上去,原因很多,比如很难调动个人的积极性、内部管理协调非常困难等。我认为还有一个重要的原因,就是方法不得当。大公司资源多,一个互联网创新项目,投入大量资源后,公司期望值高,考虑的问题自然多了,反而不容易做好。 从大公司离职出来创业,首先要“挥刀自宫”,干掉大公司这套做法,控制成本尽量少花钱,集中精力和资源解决核心的一两个问题就足够了。 不要想太多,不做太长时间的计划,尤其是计划不能太复杂!创业成功需要的是发现机会和快速突破的能力,再加一点运气。大公司的工作经验太多,有时候反而会限制自己的做法。互联网创业,越简单越单纯,越容易成功!
(1) 一个明确而且用户迫切需要的产品,很容易找到明确的用户群。这样,产品研发出来后,不容易走偏。(2) 选择的用户需求要有一定的普遍性,这点决定这个产品的未来市场前景。(3) 解决的问题少,开发速度快,也容易控制初期的研发成本和风险。(4) 解决明确问题的产品,容易给用户说清楚,推广也会相对简单。 2.极致:要在这个功能点上做到所有同类产品的极致,做到最好才能赢。 (1) 极致是互联网产品的核心,只要极致才能超出用户的口碑,形成口口相传的效应,给后期的推广带来了很大的便利。(2) 专注才能做到极致,做到极致才能击败竞争对手。 3.快:开发周期一定要控制在三到六个月的时间,一定要快。 (1) 互联网时代,用户需求变化比较快,而且竞争也比较激烈。快速的开发,容易适应整个市场的节奏,并且节约成本。(2) 用户试用过程中,如果发现问题,反应速度也要快,尽快改善尽快更新。初期,我认为要保持在一两周的更新速度。 4.口碑:初期市场营销坚持少花钱甚至不花钱,才能看出产品对用户真正的吸引力。 互联网创业的葵花宝典就是“专注”、“极致”、“快”和“口碑”! 一次完美的互联网创业,最好是技术、产品高手搭配的两三人创业,三到六个月内完成产品,再用半年到一年的时间测试完善产品,达成初步成功的门槛,再寻求融资,摸索成功的商业模式,然后投入大量的市场资源推广,形成规模化业务。 初步成功的标准,不同的业务要求不同。我有一个简单的标准供大家参考,就是产品推出半年到一年时间,网站页面过一百万PV,或者客户端产品日净增安装量1万次,而且用户数还在持续增长。达成这个目标之后,需要琢磨的事情,就是在保持增长速度的同时,如何探索好的商业模式。 | |
 (2个打分, 平均:4.00 / 5) (2个打分, 平均:4.00 / 5) |
美国康普SYSTIMAX 360超高密度光缆解决方案评析
作者 老韩 | 2011-03-16 21:17 | 类型 互联网 | 5条用户评论 »
|
文章写好,久久想不出个好名字。我列了很多备选,要么太素要么太玄,最后只能用了这个还算中性的、概括全文大意的短语。其实我很想说康普是布线领域的苹果,因为他们的产品总是领先很多,总能保证功能性能最强,还总能融入让人赞叹的创新设计。有人说没用过iphone的人从媒体评测中永远也体会不到iphone的精髓,我相信,并且认为康普的产品也是这样。 原文发于《计算机世界》。
随着互联网技术的进步,数据大集中成为当今IT行业普遍认可的一种基础设施发展模式。在这个大方向的指引下,一座座数据中心如雨后春笋般拔地而起,承担着越来越多的关键业务。近年来,移动互联网、云计算等新应用模式的兴起,又对数据中心提出了新的发展要求。用户对整体处理能力的渴望,也达到了一个前所未有的高度。 在这种情况下,几乎所有IT厂商都拿出了最先进的产品解决方案,力争在数据中心建设的大潮中取得更多的市场份额。作为基础架构领域的领导者之一,美国康普也为此对产品线的布局进行了调整。一方面,该公司原有的产品解决方案已逐步归并到技术水平和用户友好度更高的SYSTIMAX 360品牌下;另一方面,美国康普也拿出了针对未来数据中心量身订做的杀手锏——SYSTIMAX 360超高密度光缆解决方案。 从高密度到超高密度 数据中心的建设可以分为多个层面。计算、存储、数据通信等子系统和业务密切相关,可以根据实际需求分批次地进行建设;动力、散热、布线等基础架构则必须一次成型,用户在数据中心的建设初期就得充分评估,最大程度地做好预留。在美国国家标准学会(ANSI)2005年批准颁布的《数据中心电信基础设施标准》(TIA-942)中,又明确地根据基础架构中各部分的冗余程度,将数据中心分为4个级别。而冗余对布线系统最明显的影响,就是成倍增加了端口密度方面的要求。虽然我国的数据中心建设起步较晚,在空间、动力等方面还没有遇到太多问题,但在设备端口密度不断提高的今天,布线系统的瓶颈已然显现。 可以说,美国康普SYSTIMAX 360超高密度光缆解决方案的推出,具有很强的实际意义。但在没接触到产品实物之前,我们多多少少也抱有一丝怀疑。众所周知,配线架的端口密度是最早被用户关注的指标,各厂商早就在上面下足了功夫,在物理上大多做到了极限。这“超高密度”,到底因何而来?端口密度又是怎样提升上去的? 计算机世界实验室已经连续4年跟踪测试了美国康普的多款产品,亲眼见证了该公司提升配线架端口密度的历程。以1U规格的光纤配线架为例,从旧产品线到新一代的360系列产品,美国康普通过更精细化的设计,在每个模块保持标准的6或12个LC端口的前提下,将1U体积横向可以容纳的模块个数由3个提升到4个,从而达到48口、96芯的业界最高水平。当时我们认为这个记录再被打破的可能性太小了,因为无论是配线架上还是模块上,都已经没什么剩余空间。
神奇的三叶草 1U高度的空间内提供了72个端口,这种密度有点恐怖。要知道,配线架存在的一个很重要的原因就是为了方便用户进行调整,现在密密麻麻的端口占据了前面板几乎所有的空间,是否会给数据中心的管理维护造成不便? 实验室工程师所担心的,还有一个误操作的问题。在日常测试工作中,我们曾经多次遇到这样的情况:对于一些端口密度较高的产品,工程师拔插跳线时会顺带碰到周边线缆,有可能造成连接中断,尤其是那些端口呈多行多列紧密排布的设备,误操作的几率是非常大的。这种情况出现在产品测试中也就罢了,我们大不了再重复一次,损失的只是时间;可如果数据中心的管理员操作时误碰了其他跳线,影响到关键业务,也许就会造成难以估算的经济损失。
俗话说,孤木不成林,SYSTIMAX 360超高密度光缆解决方案中的配线架虽然惊艳,但若无其他“给力”的组件相配合,也无法称之为一套优秀、全面的解决方案。美国康普还提供了多种干缆、跳线及安装套件,让用户在设计数据中心布线系统时能够充分发挥出“超高密度”的优势。而我们分析了整套方案,得到的是这样一个非常清晰的信号——MPO的时代到来了。 说起来,MPO并不是什么特别新的技术。早在前些年,应用到该技术的产品解决方案就已经被推向市场,主要充当集中部署环境下干缆的角色,所占份额并不大。但随着定义40G/100G 以太网的IEEE 802.3ba标准被批准通过,数据中心的网络基础架构逐步向10G做接入、40G/100G做骨干迁移,MPO的应用场景也得以大幅增加。在SYSTIMAX 360超高密度光缆解决方案的线缆部分,美国康普提供的大多是带有12芯连接头的MPO多模光纤。它们搭配使用,现阶段可以满足10G/40G应用,未来也可以向100G平滑过渡。另一方面,使用MPO预端接光纤可以有效减少线缆体积,避免对系统散热造成影响,更适合大规模应用环境中的部署及管理。值得一提的是,这个72端口的高密度配线架后端有着足够的盘线空间,仍然可以采用最普遍的熔接方式进行部署,同时给用户提供平滑升级的能力。
后记 40G乃至100G的数据中心,离现在貌似还很遥远,但从基础架构超前的建设规律看,筹建中的数据中心都应当对此有所考虑。在我们看来,现在针对数据中心的高密度布线方案,就如同几年前比较热门的万兆UTP铜缆方案一样,很快能迎来大面积应用的一天。而美国康普SYSTIMAX 360超高密度光缆解决方案,无疑是当前最具竞争力的一个选择。 PS:感兴趣的朋友可以猛击此处下载《SYSTIMAX 360超高密度光缆解决方案-解决方案指南》、《Commscope InstaPATCH 360 Connectivity for Cisco》。搜集资料过程中偶然看到一个博科的胶片,是一篇很全面的科普内容,推荐。 | |
|
(3个打分, 平均:5.00 / 5) |




NOX – 现代网络操作系统
作者 yeasy | 2011-03-01 08:25 | 类型 互联网, 弯曲推荐, 新兴技术 | 18条用户评论 »
系列目录 Future Internet Technology[注]本系列前面的三篇文章中,介绍了软件定义网络(SDN)的基本概念和相关平台。按照SDN的观点,网络的智能/管理实际上是通过控制器来实现的。本篇将介绍一个代表性的控制器实现——NOX。 现代大规模的网络环境十分复杂,给管理带来较大的难度。特别对于企业网络来说,管控需求繁多,应用、资源多样化,安全性、扩展性要求都特别高。因此,网络管理始终是研究的热点问题。 从操作系统到网络操作系统早期的计算机程序开发者直接用机器语言编程。因为没有各种抽象的接口来管理底层的物理资源(内存、磁盘、通信),使得程序的开发、移植、调试等费时费力。而现代的操作系统提供更高的抽象层来管理底层的各种资源,极大的改善了软件程序开发的效率。 同样的情况出现在现代的网络管理中,管理者的各种操作需要跟底层的物理资源直接打交道。例如通过ACL规则来管理用户,需要获取用户的实际IP地址。更复杂的管理操作甚至需要管理者事先获取网络拓扑结构、用户实际位置等。随着网络规模的增加和需求的提高,管理任务实际上变成巨大的挑战。 而NOX则试图从建立网络操作系统的层面来改变这一困境。网络操作系统(Network Operating System)这个术语早已经被不少厂家提出,例如Cisco的IOS、Novell的NetWare等。这些操作系统实际上提供的是用户跟某些部件(例如交换机、路由器)的交互,因此称为交换机/路由器操作系统可能更贴切。而从整个网络的角度来看,网络操作系统应该是抽象网络中的各种资源,为网络管理提供易用的接口。 实现技术探讨模型NOX的模型主要包括两个部分。 一是集中的编程模型。开发者不需要关心网络的实际架构,在开发者看来整个网络就好像一台单独的机器一样,有统一的资源管理和接口。 二是抽象的开发模型。应用程序开发需要面向的是NOX提供的高层接口,而不是底层。例如,应用面向的是用户、机器名,但不面向IP地址、MAC地址等。 通用性标准正如计算机操作系统本身并不实现复杂的各种软件功能,NOX本身并不完成对网络管理任务,而是通过在其上运行的各种“应用”(Application)来实现具体的管理任务。管理者和开发者可以专注到这些应用的开发上,而无需花费时间在对底层细节的分析上。为了实现这一目的,NOX需要提供尽可能通用(General)的接口,来满足各种不同的管理需求。 架构组件下图给出了使用NOX管理网络环境的主要组件。包括交换机和控制(服务)器(其上运行NOX和相应的多个管理应用,以及1个Network View),其中Network View提供了对网络物理资源的不同观测和抽象解析。注意到NOX通过对交换机操作来管理流量,因此,交换机需要支持相应的管理功能。此处采用支持OpenFlow的交换机。
操作流量经过交换机时,如果发现没有对应的匹配表项,则转发到运行NOX的控制器,NOX上的应用通过流量信息来建立Network View和决策流量的行为。同样的,NOX也可以控制哪些流量需要转发给控制器。 多粒度处理NOX对网络中不同粒度的事件提供不同的处理。包括网包、网流、Network View等。 应用实现NOX上的开发支持Python、C++语言,NOX核心架构跟关键部分都是使用C++实现以保证性能。代码可以从http://www.noxrepo.org获取,遵循GPL许可。 系统库提供基本的高效系统库,包括路由、包分类、标准的网络服务(DHCP、DNS)、协议过滤器等。 相关工作NOX项目主页在http://noxrepo.org。 其他类似的项目包括SANE、Ethane、Maestro、onix、difane等,有兴趣的同学可以进一步研究参考。 | |
|
(4个打分, 平均:5.00 / 5) |

Mininet – “懒惰”网络研究者的福音
作者 yeasy | 2011-01-08 20:36 | 类型 互联网, 新兴技术 | 6条用户评论 »
系列目录 Future Internet Technology
【摘要】在本系列前两篇文章里,我们分别介绍了软件定义网络的两大利器——OpenFlow和Open vSwitch。不少研究者可能很有兴趣尝试一下,却拿不出太多的时间。本文将介绍一套强大的轻量级网络研究平台——mininet,通过它相信大家可以很好地感受到软件定义网络的魅力。
概述篇作为研究者,你是否想过,在自己的个人笔记本上就可以搭建一套媲美真实硬件环境的复杂网络,并轻松进行各项实验?无论是用专业级的硬件实验平台,还是用传统的虚拟机,都显得太过昂贵,且十分不方便进行操作。如果你有类似的需求,不妨试试mininet,绝对是“懒惰”却又追求效率的研究人员的福音。
stanford大学Nick McKeown的研究小组基于Linux Container架构,开发出了这套进程虚拟化的平台。在mininet的帮助下,你可以轻易的在自己的笔记本上测试一个软件定义网络(software-defined Networks),对基于Openflow、Open vSwitch的各种协议等进行开发验证,或者验证自己的想法。最令人振奋的是,所有的代码几乎可以无缝迁移到真实的硬件环境中,学术界跟产业界再也不是那么难以沟通了。想想吧,在实验室里,一行命令就可以创建一个支持SDN的任意拓扑的网络结构,并可以灵活的进行相关测试,验证了设计的正确后,又可以轻松部署到真实的硬件环境中。
mininet作为一个轻量级软定义网络研发和测试平台,其主要特性包括
实战篇获取镜像官方网站已经提供了配置好相关环境的基于Debian Lenny的虚拟机镜像,下载地址为http://openflowswitch.org/downloads/OpenFlowTutorial-081910.vmware.zip,压缩包大小为700M左右,解压后大小为2.1G左右。虚拟机镜像格式为vmware的vmdk,可以直接使用vmware workstation或者virtualbox等软件打开。如果使用QEMU和KVM则需要先进行格式转换。后面我们就以这个虚拟os环境为例,介绍mininet的相关功能。
登录镜像默认用户名密码均为openflow,建议通过本地利用ssh登录到虚拟机上使用(可以设置自动登录并将X重定向到本地),比较方便操作。
简单测试创建网络mininet的操作十分简单,启动一个小型测试网络只需要下面几个步骤。
登录到虚拟机命令行界面,打开wireshark,使其后台运行, 命令为sudo wireshark &
启动mininet,命令为sudo mn,则默认创建如下图所示的网络拓扑。
 此时进入以mininet>引导的命令行界面
好了,从现在开始,我们就拥有了一个1台控制节点(controller)、一台交换(switch)、两台主机(host)的网络,并且用wireshark进行观测。下面进行几项简单的测试。
查看信息查看全部节点:
mininet> nodes
available nodes are:
c0 h2 h3 s1
查看链路信息:
mininet> net
s1 <-> h2-eth0 h3-eth0
输出各节点的信息:
mininet> dump
c0: IP=127.0.0.1 intfs= pid=1679
s1: IP=None intfs=s1-eth1,s1-eth2 pid=1682
h2: IP=10.0.0.2 intfs=h2-eth0 pid=1680
h3: IP=10.0.0.3 intfs=h3-eth0 pid=1681
对节点进行单独操作
如果想要对某个节点的虚拟机单独进行命令操作,也十分简单,格式为 node cmd。例如查看交换机s1上的网络信息,我们只需要在执行的ifconfig命令前加上s1主机标志即可,即 s1 ifconfig,同样,如果我们想用ping 3个包的方法来测试h2跟h3之间连通情况,只需要执行 h2 ping -c 3 h3 即可。得到的结果为
mininet> h2 ping -c 3 h3
PING 10.0.0.3 (10.0.0.3) 56(84) bytes of data.
64 bytes from 10.0.0.3: icmp_seq=1 ttl=64 time=7.19 ms
64 bytes from 10.0.0.3: icmp_seq=2 ttl=64 time=0.239 ms
64 bytes from 10.0.0.3: icmp_seq=3 ttl=64 time=0.136 ms
— 10.0.0.3 ping statistics —
3 packets transmitted, 3 received, 0% packet loss, time 2006ms
rtt min/avg/max/mdev = 0.136/2.523/7.194/3.303 ms
在本操作执行后,可以通过wireshark记录查看到创建新的流表项的过程,这也是造成第一个ping得到的结果偏大的原因。更简单的全网络互ping测试命令是pingall,会自动所有节点逐对进行ping连通测试。
常用功能快捷测试除了cli的交互方式之外,mininet还提供了更方便的自动执行的快捷测试方式,其格式为sudo mn –test cmd,即可自动启动并执行cmd操作,完成后自动退出。
例如 sudo mn –test pingpair,可以直接对主机连通性进行测试,sudo mn –test iperf启动后直接进行性能测试。用这种方式很方便直接得到实验结果。
自定义拓扑mininet提供了python api,可以用来方便的自定义拓扑结构,在mininet/custom目录下给出了几个例子。例如在topo-2sw-2host.py文件中定义了一个mytopo,则可以通过–topo选项来指定使用这一拓扑,命令为
sudo mn –custom ~/mininet/custom/topo-2sw-2host.py –topo mytopo –test pingall
使用友好的mac编号默认情况下,主机跟交换机启动后分配的MAC地址是随机的,这在某些情况下不方便查找问题。可以使用–mac选项,这样主机跟交换机分配到的MAC地址跟他们的ID是一致的,容易通过MAC地址较快找到对应的节点。
使用XTerm通过使用-x参数,mn在启动后会在每个节点上自动打开一个XTerm,方便某些情况下的对多个节点分别进行操作。命令为
sudo mn -x
在进入mn cli之后,也可以使用 xterm node 命令指定启动某些节点上的xterm,例如分别启用s1跟h2上的xterm,可以用
xterm s1 h2
链路操作在mn cli中,使用link命令,禁用或启用某条链路,格式为 link node1 node2 up/down,例如临时禁用s1跟h2之间的链路,可以用
link s1 h2 down
名字空间默认情况下,主机节点有用独立的名字空间(namespace),而控制节点跟交换节点都在根名字空间(root namespace)中。如果想要让所有节点拥有各自的名字空间,需要添加 –innamespace 参数,即启动方式为 sudo mn –innamespace
其他操作执行sudo mn -c会进行清理配置操作,适合故障后恢复。
总结篇除了使用mn命令进行交互式操作以外,mininet最为强大之处是提供api可以直接通过python编程进行灵活的网络实验。在mininet/example目录下给出了几个python程序的例子,包括使用gui方式创建拓扑、运行多个测试,在节点上运行sshd,创建多个节点的tree结构网络等等。运行这些程序就可以得到令人信服的结果,而且这些程序大都十分短小,体现了mininet平台的强大易用性。
另外,限于篇幅,本文仅对mininet做了较简略的介绍,更全面的版本可以从这里找到。此外,也建议有兴趣做深入研究的朋友通过阅读参考文献,进一步了解更多有趣内容。
参考
<1> A Network in a Laptop : Rapid Prototyping for Software-Defined Networks, Bob Lantz, Brandon Heller, Nick Mckeown, ACM Hotnets 2010;
| |
|
(2个打分, 平均:4.50 / 5) |
Facebook超越Yahoo!成为第二大媒体视频浏览来源
作者 高飞 | 2010-12-24 01:02 | 类型 专题分析, 互联网, 行业动感 | 2条用户评论 »
|
这个标题看起来有点绕,实际上这个统计的是,在各家媒体网站上浏览视频的点击来源。像笔者,即使要看CNNmoney的Cisco CEO专访视频,也很少直接去访问CNNmoney,多半是看Yahoo财经有关思科的新闻点击过去的,于是CNNmoney就把笔者的这个点击来源算在雅虎头上。这就是本文所讨论的统计值。 显然,Google仍然是最大的来源。来自搜索的点击最多,这没什么奇怪的。第二大来源,很久以来一直是雅虎,因为雅虎有来自搜索和门户的广大资源。但是根据Online Video & The Media Industry的报告,2010年第三季度,Facebook异军突起超越了雅虎,成为了浏览媒体网站视频的第二大来源。这份报告由Tubemogul和Brightcove两家公司联合完成,统计的范围主要是由Brightcove用户发布的视频,集中在报纸、杂志、广播、品牌宣传和在线媒体。不要小看“Brightcove用户”这个词,下一段介绍了该公司大家就知道了。 Tubemogul公司(tubemogul.com)位于加州Emeryville,2006年11月成立,经过两轮融资共获得投资1450万美元。这是一个视频广告和分析平台,目的是高度针对性的联系广告商与用户。而另一家Brightcove(brightcove.com )位于马萨诸塞州剑桥市,2004年初成立,迄今为止四轮共获得了一亿三百万美元融资。这是一家典型的SaaS(Software-as-a-Service)公司;Brightcove在线视频平台是目前应用最广泛的发布传播专业视频的软件。公司客户来自45个国家,数目超过1500,包括了世界上最大的几家新闻和娱乐媒体以及Fortune 1000公司。这些公司使用Brightcove来进行视频内容管理、发布、syndication、视频广告分析等等。因此从这两家公司出炉的这份报告,具有相当的代表性。 2010年第三季度,细数各个媒体网站视频点击来源份额,Facebook的达到了9.6%,Google的份额超过50%,但是比2010年第二季度的60+%下降了不少。很有意思的是,来自搜索的份额,无论是Google,Yahoo还是Bing,都有不同程度的下降。 用户的粘度用其观看视频的分钟来统计,为了去掉“最高分”和“最低分”的干扰,只算平均时间低于两分钟的视频浏览。平均粘度最高的用户居然是来自Twitter的。如果把媒体网站细分如下图之表示,则值得进一步解读结果。Twitter的用户主要“粘”在广播公司、品牌宣传和在线媒体网站上;而Facebook用户更喜欢粘在杂志和报纸网站上;Google用户则最喜欢报纸网站,愿超其它。最直观的解读就是,人们去Google是寻求“及时快速”的信息,因此这种用户多半会喜欢新闻类的视频而不是娱乐类的。Twitter用户特别喜欢品牌宣传,是不是意味着用户群的收入、品味和年龄其实很集中? 这份报告还有许多其他有趣的信息,比如在线视频角逐中,各种媒体网站发力角度之不同等等。报告全文在这里:Online Video & The Media Industry。
| |
|
(2个打分, 平均:1.00 / 5) |


Fortinet:黄金十年
作者 老韩 | 2010-12-22 15:57 | 类型 互联网, 网络安全 | 56条用户评论 »
|
与UTM共同成长 十年前,应用层安全的概念还并未被人们所熟知,当时的网络与应用条件也暂不需要部署在网络边缘的安全设备提供4层以上的安全特性。但从各方发展角度看,安全攻防向应用层转移又是不可逆转的趋势,谁能在产品研发和市场培育上占得先机,谁就有可能在未来获得回报。Fortinet就是在这样的背景下成立的,该公司回避了当时颇受关注的防火墙性能大战,将重点放在了新一代安全产品的研发上。 实际上,并无任何证据可以证明是Fortinet第一个推出了集成多种安全功能(包括应用层安全)的设备,但可以肯定的是,该公司的产品在功能、性能和稳定性等方面终于满足了用户需求,得到市场的认可。2004年,IDC经过长期跟踪,正式将这类新兴产品定义为UTM,并明确要求此类产品必须在单一硬件中至少提供防火墙、IPS和网关防病毒功能。毫无疑问地,Fortinet推出的FortiGate系列产品成为了UTM的第一个范本。 随着时间的推移,应用层安全的重要性日益提升,有越来越多的用户认识到自己的网络系统需要全方位的安全防护,高集成度、低成本的UTM显然是很合适的选择。与此同时,技术发展导致了UTM综合性能的大幅提升,加之可以大幅简化体系架构或方案的复杂度,连行业用户和运营商都开始部署此类产品。所以据统计,全球UTM市场近年来保持着高速增长,并有望在不久的将来达到数十亿美金的规模。而对于UTM产品收入占到整体收入90%的Fortinet来说,自然是受益颇丰,企业也因此得以快速发展。 时至今日,Fortinet成功晋级为全球范围内的一线网络安全产品与解决方案提供商。该公司目前拥有一千多名员工,建立了全球化的销售服务体系,并于2009年年底在美国纳斯达克成功上市,近期市值高达25亿美元。在保持UTM领域领导者地位的同时,Fortinet也加强了其他产品线的建设,目前可提供包括Web应用安全、邮件安全、数据库安全、终端安全和安全管理在内的多套独立产品解决方案。 特立独行的产品架构 很多业内人士认为,在应用层安全时代,“ASIC已死,多核当立”。Fortinet则不这么看,该公司深谙技术为用户需求服务的道理,在产品设计方面有着自己独特的思路。作为旗下最受市场认可的产品,FortiGate系列UTM虽然一直在推陈出新,逻辑结构却从未改变。除了部分低端桌面级产品,包括采用ATCA架构产品的处理板在内的所有中高端型号均采用了通用处理器搭配自主知识产权的FortiASIC专有加速芯片的方式,实现安全业务的高性能处理。此外的网络、安全业务和设备的管理,则通过FortiOS软件系统完成。 由于网络层安全业务和应用层安全业务的处理机制有着很大不同,加速芯片也需做有针对性的设计。FortiASIC-NP网络处理器采用在线模式工作,直接处理数据包,对防火墙和VPN功能进行加速。此外,该芯片还具有基于异常的入侵防御及流量整形的功能,基本上涵盖了网络层安全的所有方面。FortiASIC-CP内容层处理器则工作在旁路模式,受通用处理器调用,协助实现高速的加解密和基于特征的匹配工作。
在最高端的产品设计上,Fortinet采用了分布式处理的思路,借助标准的ATCA机框推出了3种规格的FG5000集群式安全平台。其中最高端的型号具有14个扩展槽位,最多可插入12块逻辑结构相同的处理板,以负载分摊的方式作用于剩余的接口模块,实现性能的线性增长。在满配情况下,FG5000将拥有160Gbps的防火墙吞吐量、超过10Gbps的IPS、病毒过滤性能、80万/秒的新建链接能力和最大8000万个并发连接,可以满足任何高端用户的需求。 | |
|
(6个打分, 平均:3.00 / 5) |


给力吧,x86(2)——12月13日测试记录
作者 老韩 | 2010-12-20 19:36 | 类型 互联网, 网络安全, 通讯产品 | 176条用户评论 »
|
系列内容:
1个月前的测试让人见识了Panabit这一年来的进步,也看到了x86平台在通信领域的潜力。不过,上次的测试并不细致,1个N270平台也不能代表一切,所以我和Panabit团队达成一致,在接下来的一段时间内以细水长流的形式保持一系列测试合作。 为了让测试不那么无聊,我打算时不时地换种形式娱乐一下。比如这次的测试就是一道问答题,我提出了一个性能目标——2个千兆口64Byte裸奔线速,看看PanaOS用什么档次的平台能够达到。插一句,我从来不觉得裸奔没意义,相反认为意义重大,因为转发能力是一切的基础。并且曾经听几个国内安全厂商的朋友说过,他们做产品规划的时候都用这个小包裸奔2G的数字作为千兆低端和千兆中端的分界线。
看看Panabit团队拿了一台什么样的设备来应战:汇尔(HOLL)科技IEC-516P,Atom D525/1G RAM/i82574L x 6,一台看起来很实用的1U Box。从PCB上看,应该可以有两组硬件Bypass,还有3个SATA和一个PCIe 1x接口。Atom,难道这次又用它来挑战IT人的传统认识?不费脑子了,先测了再说。
测试结果里隐藏了太多的玄机,比如2个GE做一组桥的时候,D525平台下的性能怎会和上次的N270基本一样?比如6个GE做3组桥的时候,平均延迟作何解释?再比如,多路桥的大包测试结果和N270基本一致,瓶颈又出在哪? 不过,和整机64Byte吞吐量2.1Gbps(3.12Mpps)的结果相比,一切都是浮云了。一个在x86工控机中价格优势最明显的BOX,裸奔出这样的性能,还真是头回得见。立志进入嵌入式领域的英特尔应该注意了,在Wind River Network Acceleration Platform还没有成功案例之前,PanaOS也许是x86平台上性价比最高的选择,是不是考虑给Panabit提供些特别支持呢? 从我们的角度看,Panabit自诞生以来一直保持着技术和模式上的双重创新,得到市场认可并成功地活了下来,对整个行业都有着重大的意义。说颠覆还太早,但它确实已经成为国内通信安全圈中不容忽视的新兴力量,有着相当不错的发展前景。基于此,我们团队一致决定授予Panabit 计算机世界2010年年度创新奖。 | ||||||||||||||||||||||||||||||||||||||||||||
|
(9个打分, 平均:3.22 / 5) | ||||||||||||||||||||||||||||||||||||||||||||

工具箱
本文链接 |
|
打印此页 | 176条用户评论 »