




浅谈高端CPU Cache Page-Coloring(6)
作者 陈怀临 | 2011-05-30 22:58 | 类型 专题分析, 芯片技术 | 20条用户评论 »
系列目录 高端CPU Cache Page Coloring前面5节阐述了大CPU大Cache的Cache Page-Coloring的一些基本概念。主要是通过妈咪的包厢运作制度来作为各位弟兄们比较熟悉的场景,从而达到融会贯通的。 在Cache Page-Coloring方面,一个前提是“里面放了N个长凳子的包厢制度”–Set Associative的Cache。否则,一切无从谈起。 这一节谈一下目前大CPU中的L3 Cache的一些问题。通常我们说LLC–Last Layer Cache。 目前市场上不少芯片都有了On-Die的L3 cache,例如Intel的Nehalem-EX, Westmere,IBM的Power7,RMI的XLP,Tilera等等。 与L1和L2的Cache相比,L3 cache的设计和管理方式有相同的地方,也有不一样的地方。 这里比较容易犯迷惑。 1。L3也是Set/Associative的。换言之,学术界和工业界没有,也没有傻到整一个新的Cache机制。从而,Page Coloring的各种思想和算法是而且当然是可以apply到L3 cache中去的。 3。对L3 cache理解里最容易出错误的就是这个通常不是Local bus的Interconnect结构,例如Ring。从而对其寻址方式和其结构方式造成混淆。请记住:Local Bus的直接拿Index bit来寻址和通过Pa做Hash来寻址,这是一个微结构的事情(Micro-Arch),而非结构(Arch)的事情。在结构上,L3仍然是一个Set/Associate的Cache。例如Nehalem-EX(Beckton)的24M的24Way的L3 Cache。这就说明,这个L3 Cache有(24*2^20)/(24 * 2^6) = 2^14=64K Sets. 显然,通过我们上述几节的分析,在Intel CPU上,一个44位物理地址的0-5是cache offset;6-19是Set的Index bit。我们会在后续文章中对Intel的L3 Cache的微结构做一些探讨,例如其hash机制。 下面是一些相关CPU(Nehalem-EX;XLP-832
| |
  (2个打分, 平均:4.00 / 5) (2个打分, 平均:4.00 / 5) |




盛科的新Baby–ManhattanTM和BrooklynTM
作者 陈怀临 | 2011-04-19 07:38 | 类型 专题分析, 芯片技术 | 43条用户评论 »
|
【陈怀临:恭喜盛科。下面是我拿到的新闻稿。及时的给同学们汇报。后续分析会陆续展开。。。。。。】 苏州2011年4月19日电 /美通社亚洲/– 盛科网络(苏州)有限公司(以下简称“盛科”),是领先的核心芯片及定制化网络解决方案的提供商,日前宣布将于2011年第三季度推出两款以太网交换核心芯片 CTC6028(ManhattanTM)和CTC5048 ( BrooklynTM ),从而与现有的 CTC6048(HumberTM )包交换核心芯片和 CTC8032 ( RichmondTM )交换网核心芯片一起,构建完整的以太网交换芯片产品系列 TransWarpTM。该产品系列,为网络设备提供商构建从固定配置的盒式系统到模块化分布式架构的网络设备提供了全面、有竞争力和差异化的芯片解决方案。 CTC6028和 CTC5048均采用65nm CMOS 工艺,拥有业界领先的集成度,内部集成包处理引擎、流量管理引擎和上联接口,在功耗方面有着良好的表现。CTC6028提供68Gbps的处理能力,具备外接 TCAM 和 SRAM 的表项扩展能力,在满足电信和企业高密度汇聚网络的高扩展,高性能应用要求的同时,最大程度降低设备成本。CTC5048提供与 CTC6048相同的100Gbps 的处理能力,可满足企业和电信城域汇聚应用的高性价比要求。 CTC6028和 CTC5048沿用了盛科 CTC6048独特而灵活的产品架构,提供集Ethernet/IP/MPLS/MPLS-TP 于一体的融合设计,可以满足当前和未来多种业务和网络承载需求。以下是这两款芯片的重要特性: 基于 CTC6048开发的软件可无缝移植到基于 CTC6028与 CTC5048的硬件平台上。目前,完整的具备L2/L3/MPLS 特性的 CTC6048参考设计已经开始供应给客户测试。基于 CTC6028与CTC5048的软件设计亦可以基于此评估板进行设计。 美国 Linley Group 的高级分析师 Jag Bolaria 表示:“以太网承载在3G/4G 移动通讯网络,视频网络,数据中心和云计算领域的应用越来越普及。盛科的 TransWarp 芯片系列为城域以太网和数据中心网络等应用领域提供了极具竞争力的产品。它能很好的帮助 OEM 厂商根据自身需要构建从边缘设备到核心设备的差异化网络解决方案,并且可以基于统一的芯片架构进行软件复用。” “这两款芯片的问世,标志着盛科 TransWarp 产品线的进一步丰富,能够为三网融合、城域以太网接入和汇聚网络、分组传送网络(PTN)、光线路终端设备(OLT)等多种应用提供更多高性价比的核心芯片。”盛科首席技术官古陶表示。“盛科还将发布一系列基于下一代技术的高性价比的接入和汇聚芯片,从而覆盖更多的细分市场,可为设备商提供更加完整的解决方案。” | |
|
(4个打分, 平均:5.00 / 5) |
Intel . E7 8800/4800
作者 陈怀临 | 2011-04-08 19:58 | 类型 芯片技术 | 2条用户评论 »
Sandy Bridge核外架构的进化——英特尔Sandy Bridge 处理器分析测试之四
作者 Lucifer | 2011-04-01 07:50 | 类型 专题分析, 芯片技术 | 4条用户评论 »
系列目录 英特尔Sandy Bridge处理器分析测试
原文发布于《计算机世界》2011年第8期,有修订 Sandy Bridge核外架构的进化 计算机世界实验室 盘骏 和微架构方面一样,Sandy Bridge的架构方面也具有了很大的变化。这个变化来自两个方面的考虑:性能和可扩展性,其中后者包括了要面对越来越多的处理器核心的问题,还有要面对来自GPU挑战的问题。针对GPU的压力,英特尔一方面采取了更宽的256位AVX向量运算提升CPU处理能力,一方面采取了在CPU内直接融合GPU的方法。关于GPU的部分可以写出多个长篇,因此这里主要谈及Sandy Bridge其它方面的架构变化。
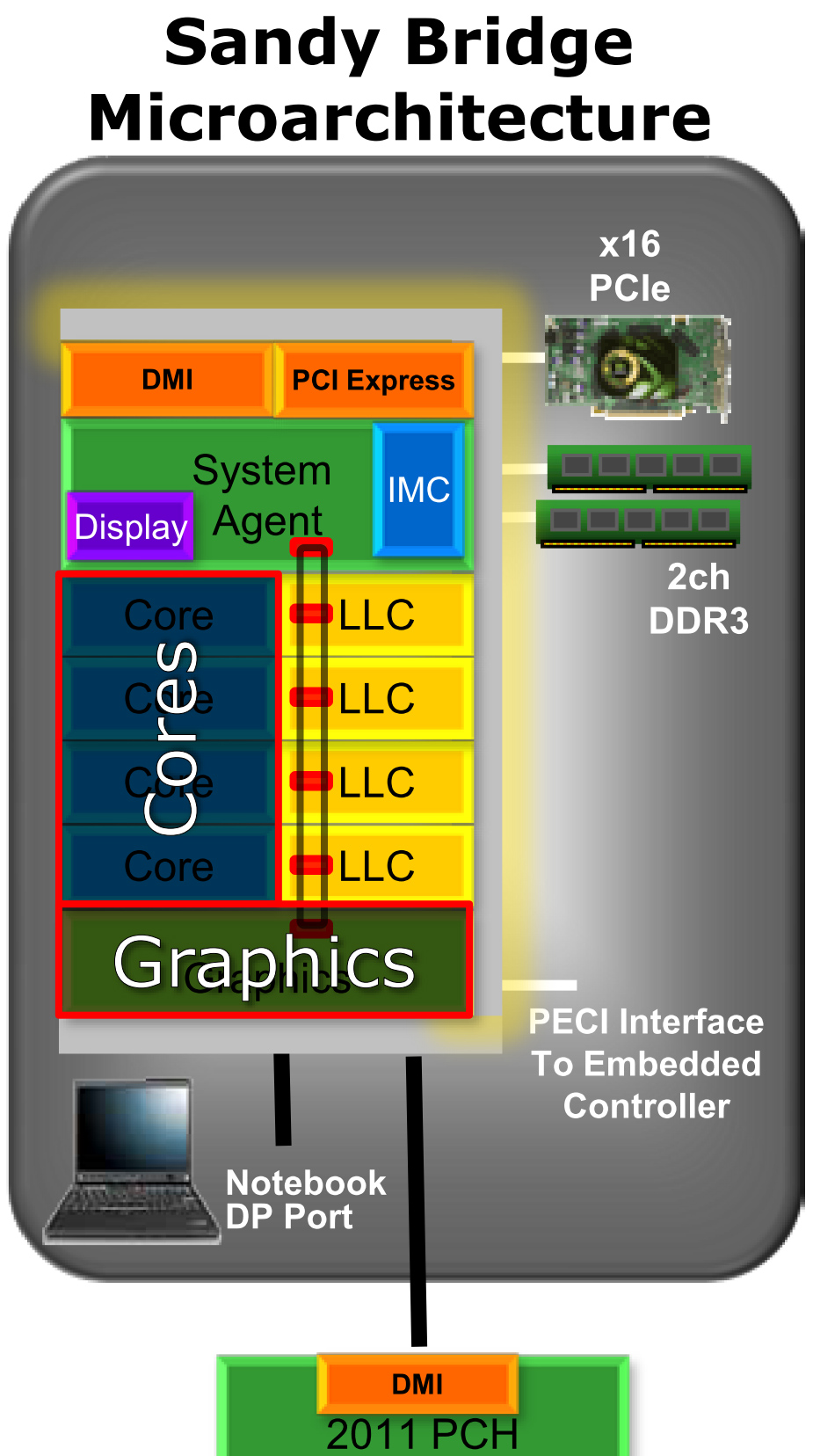
这个变化就是Sandy Bridge采用了新的Ring Bus环形总线来连接各个CPU核心、LLC缓存(就是L3缓存)、融合进去的GPU以及System Agent(就是系统北桥)部分。自从Nehalem开始使用融合核心策略后,不同产品线的处理器都基于同一种核心,只是具有不同的核外架构(称为Uncore架构),这个核外架构在不同的产品线上必须进行不同的设计,对应地芯片组也要进行变化。在核心数量比较少的时候,这很容易办到,然而在高端服务器上,核心数量很高,这种方式就难以具有匹配的性能,并且开始变得难以实现。实际上,高端8核心的Nehalem-EX处理器就采取了和桌面/移动端完全不同的Uncore架构:使用了一个环形总线,而在后来加入GPU的Westmere,新加入的GPU迫使内存控制器和CPU核心分立,并和GPU一起集成到一个相对落后的45nm制程的芯片上,影响到了性能和功耗。现在,这个环形总线技术被应用到了Sandy Bridge全线产品线上来。 革命性的环形总线
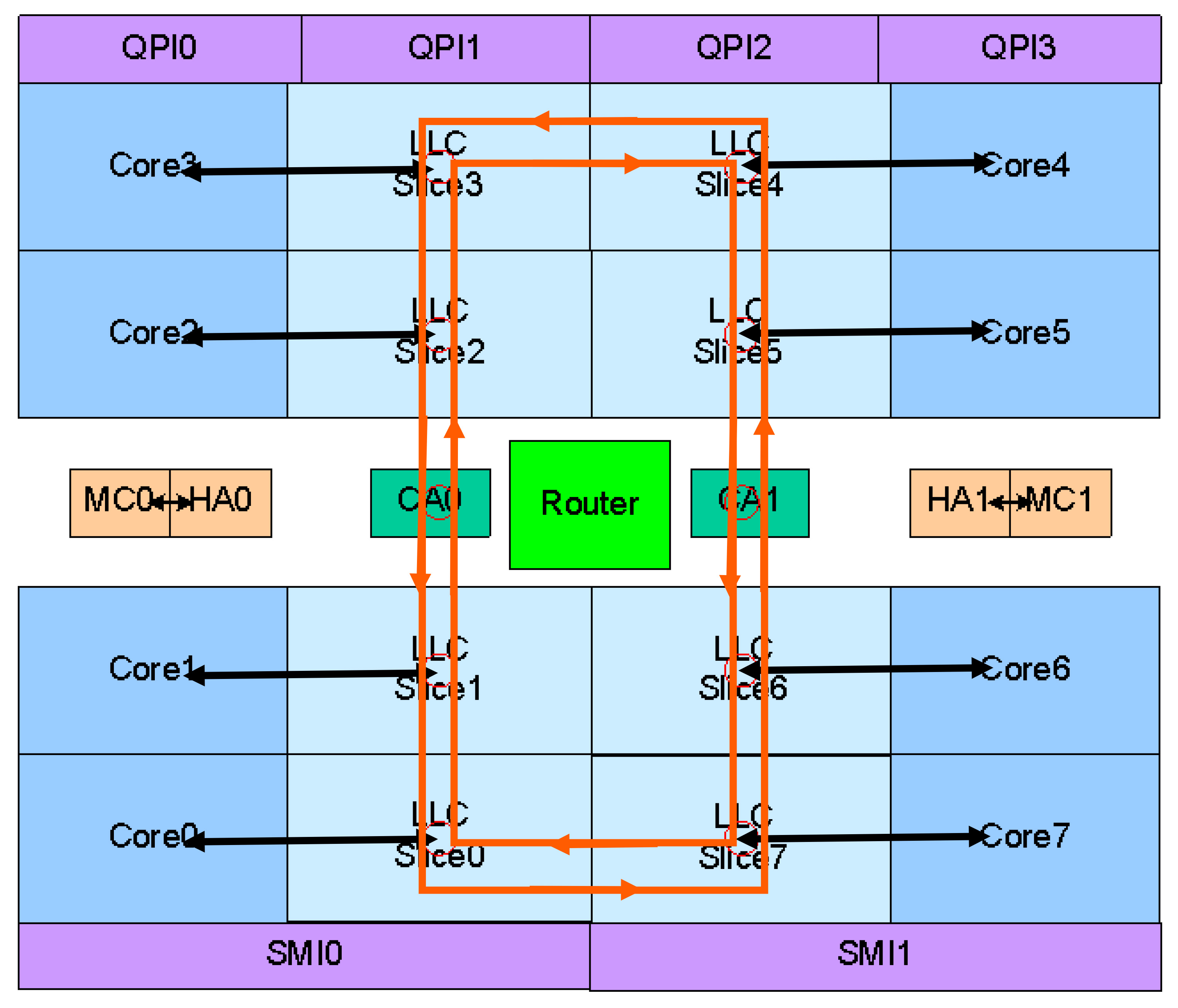
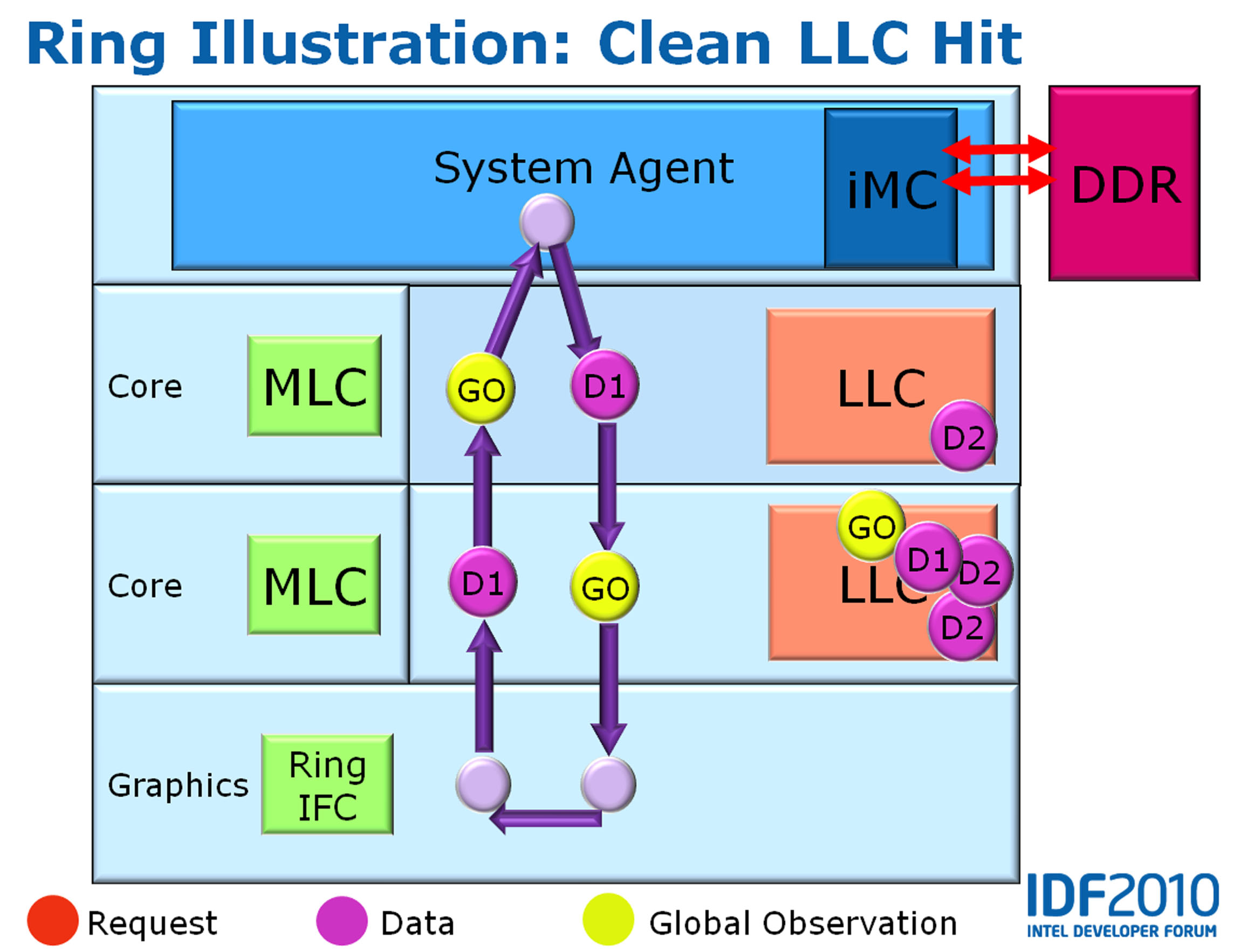
这个环形总线其实由四条独立的环组成,分别是数据环(Data Ring)、请求环(Request Ring)、响应环(Acknowledge Ring)、侦听环(Snoop Ring)。其中用来传输数据的数据环的宽度是32B(256bit),刚好是L3缓存线的一半。和Nehalem-EX的一样,这个数据环应该还是双向的,这样通过自动选择最近的线路,对目标的存取延迟可以降低到平均只有一个环的一半。 Sandy Bridge环形总线上分布着多个Ring Stop,叫做“站台”,这个“站台”和Nehalem-EX的并不太一样,其实仔细看的话,Sandy Bridge的环形总线和Nehalem-EX的也不太一样。Nehalem-EX的环显得更大一些,每个CPU/LLC块上只有一个连接点,而Sandy Bridge的显得很纤细,每个CPU/LLC块上具有两个连接点,这种差异的具体细节尚不清楚。 环形总线是全流水线化的,并且运行在核心频率/电压上,因此其带宽会根据不同的型号/工作状态而变化,并且可以根据加入站台的数量而扩展。当然,站台数量的增加会增长总线的宽度,并会对应地增加延迟,每个站台之间的传输时间是一个时钟周期。理论上,3.4GHz的Sandy Bridge每个站台可以具有108.8GB/s的带宽,4个核心就具有435.2GB/s的理论带宽,由于数据经过不同的站台的时候,该站台需要等待而无法传输数据,因此实际的带宽无法达到理论值。 LLC:L3缓存的变化 环最主要的作用是将CPU核心与L3缓存联结起来,L3缓存是处理器的最低一级缓存,因此也叫Last Layer Cache(LLC)。每一个CPU/LLC块上具有一个称为Interface Block(接口块)的部件来负责和Ring通信,每个接口块上包含了一个独立的缓存控制器,负责回应缓存请求、维持一致性和排序,并在L3缓存未命中、侦听以及遇到不可缓存请求时和System Agent通信。实际上,Sandy Bridge实现了一个分区化的分布式仲裁缓存架构。
除去使用环形总线的EX系列,Nehalem/Westmere的L3是一个单块的大缓存,具有统一的32B(256bit)带宽,到了环形总线架构之后,就不再是这样了。和Nehalem-EX/Westmere-EX一样,Sandy Bridge将LLC分成多个具有32B宽度接口的Slice,物理地址还使用Hash机制分布到所有的缓存块上,因此实际上所有的缓存块都可以同时运作,增加了带宽、简化了一致性问题并避免了热区效应,其性能和没采取环形总线的时候具有着巨大的提升。 每一个LLC缓存块都具有和原来Nehalem/Westmere的大缓存块类似的结构,在桌面处理器上,每个核心将会对应一个LLC缓存块,而每个2MB容量的LLC块属于16路组相连。在服务器产品线上,每个核心仍然对应一个缓存块,然而由于去掉了GPU模块,因此LLC缓存块获得了更大的面积,其容量提升到了2.5MB,对应地,组相连也提升到20路,这些进一步提升了其缓存命中率表现。Sandy Bridge的L3缓存仍然使用了包含式的设计,在上级缓存上具有的内容在L3缓存上具有同样的副本,和Nehalem一样,Sandy Bridge也使用核心有效位来起到侦听过滤器的作用,只是增加了GPU对应的位,因为Sandy Bridge的缓存是CPU、GPU共享。 除了缓存的分布式仲裁、运作带来的高带宽之外,Sandy Bridge的缓存延迟实际上也得到了降低,大约从原有的35-40个时钟周期降低到26-31个时钟周期。延迟的降低一部分是因为小的缓存块本身就具有较低的延迟,存取对应的标记和数据都比原有的单个大缓存块要快。延迟降低的另一个原因是现在LLC缓存运行的频率和核心频率保持了一致。在Nehalem/Westmere上,LLC缓存运行于Uncore频率,通常是比核心频率要低的。一致的运行频率还避免了不同频率区间传递信号的惩罚,最终让Sandy Bridge延迟表现更好。 System Agent:更快速的北桥 System Agent系统代理扮演原有的北桥角色,连接内存控制器、PCI Express总线以及PCH(类似南桥芯片),此外还带有PCU功率控制单元管理其他部件的频率/电压,实现Turbo Boost 2.0功能,System Agent还负责引出GPU的显示输出。在带有GPU的Sandy Bridge处理器上,CPU/LLC、GPU运行于动态的电压和频率,而System Agent则运行于固定的电压和频率。和传统的分立北桥和上一代Lynnfield的多芯片同封装相比,完全集成在一起的System Agent尽可能地消除了各个部件间的联线,可以提供更好的延迟表现。 通过使用了新的环形总线,Sandy Bridge以更有效率的方式对CPU、LLC、GPU和System Agent进行了组织,提供了更高的内部带宽和更低的L3存取延迟,并且可以很好地融合新加入的GPU模块,并适应高端服务器市场上的大数量处理器核心场景。在下回,笔者将介绍Sandy Bridge全新的GPU部件,敬请期待。 | |
 (6个打分, 平均:3.50 / 5) (6个打分, 平均:3.50 / 5) |
Finfet+平面型架构混合体:传Intel近期将公布22nm节点制程工艺细节
作者 cracked | 2011-03-28 21:39 | 类型 芯片技术, 行业动感 | 2条用户评论 »
|
【原文可参阅http://www.cnbeta.com/articles/137979.htm】 据消息来源透露,Intel公司近期可能会公开其22nm制程工艺的部分技术细节,据称Intel的22nm制程工艺的SRAM部分将采用FinFET垂直型晶体管结构,而逻辑电路部分则仍采用传统的平面型晶体管结构。消息来源还称Intel“很快就会”对外公开展示一款基于这种22nm制程的处理器实物。不过记者询问Intel发言人后得到的答复则是:”我们不会对流言或猜测进行评论。” 尽管早在2009年Intel高管Mark Bohr便曾公开过其22nm制程SRAM的部分细节和实物,不过按Intel发言人的话说:“我们目前为止一直对22nm制程技术的技术细节守口如瓶。”过去几个月以来,外界普遍猜测Intel近期会公布其22nm制程的有关技术细节和产品实物,而且Intel的发言人也没有否认这种说法。 据消息来源称,Intel这种Finfet/平面型晶体管结构混合的方法可令SRAM部分的晶体管密度更高,且更易于对Vmin值进行控制,与此同时,相对较复杂的逻辑电路部分采用平面型晶体管结构则可降低工艺的复杂性。多年来,出于商业宣传的目的,Intel一直将自己所使用的垂直型晶体管技术称为“三栅( TriGate)架构”,不过三栅晶体管与Finfet并不存在本质的区别,均是通过采用沟道被多个栅极围绕的设计来增强对沟道的控制。 假如这则消息属实的话,那么5年之后Intel在制程技术方面无疑又站到了业界的最前列。5年前的2007年1月份,Intel宣布在45nm制程产品中集成HKMG工艺,并同时推出了基于这种技术的多款处理器样品。 去年举办的IEDM大会上,Intel没有发表任何有关的重要文件,此举引发外界的广泛猜疑,许多人均认为此举表明Intel很快就会推出自己的三栅技术。 假如消息为真,那么Intel在应用Finfet垂直型晶体管技术方面显然又一次领先了对手,此举无疑将对其它芯片制造公司制造一定的压力,有可能会促成这些公司对自己的20nm/14nm技术发展路线图进行一些修改。预计一些公司未来将使用Finfet技术,比如台积电便是Finfet工艺的倡导者之一。而另外一些公司如意法半导体等则明确表示将在14nm制程节点启用平面型的全耗尽型SOI技术(FDSOI) 去年6月份,台积电高级副总裁蒋尚义宣布公司将于14nm制程节点转向使用Finfet技术,并对有关的设计工具,技术体系等进行重新设计。有消息来源表示台积电若想如期在14nm制程转向Finfet技术,需要作为其客户的芯片设计厂商从现在起就开始变更芯片设计方法,这样届时其产品才能用上14nm制程的Finfet技术来制作。因此这位消息来源认为台积电在14nm制程应用的初期会首先推出一款基于平面型体硅制程的工艺,然后才推出基于Finfet技术的高性能制程。 IBM方面则表现得有点“脚踩两只船”,他们在往届大会上发布的文章既有涉及Finfet,也有涉及FDSOI工艺。而GlobalFoundries则在其举办的2010年的一项会展仪式上明确表示22/20nm制程节点会继续使用平面型晶体管技术,不过HKMG制造工艺方面则会从现用的Gate-first改为Gate-last,他们还将继续同时提供基于体硅和SOI两种制程的产品。不过GlobalFoundries目前为止并未透露其14nm制程节点的有关动向。 2009年,Intel曾展示了基于22nm制程的SRAM试制产品,当时他们宣称其22nmSRAM包含有3.64亿个记忆单元,并称其SRAM单元晶体管采用了两种不同的尺寸设计,一种为0.108×0.108平方微米结构,另外一种则为0.092×0.092平方微米结构,前面一种结构的单元晶体管据称专为低电压条件下的操作优化,而后面一种结构的晶体管则专为提高晶体管密度而优化,Intel并称这块试制芯片内含29亿个晶体管。 CNBeta编译 | |
|
(1个打分, 平均:1.00 / 5) |
Juniper的QFabric视频集锦
作者 陈怀临 | 2011-03-04 22:13 | 类型 芯片技术, 通讯产品 | 15条用户评论 »
|
【陈怀临注:The essence of networking is not routing, but switching-Huailin Chen。最后那个视频的演讲者就是Juniper的灵魂和领袖–Dr. Pradeep Sindhu】 | |
|
(3个打分, 平均:5.00 / 5) |
Xilinx,Zynq,Cortex-A9,15个美刀
作者 KISS | 2011-03-04 20:50 | 类型 芯片技术, 行业动感 | 6条用户评论 »
|
[注:用的Xilinx的新闻稿,发上来供讨论。15个美刀的起价还是出乎意料,和之前嵌入PowerPC的virtex系列相比,Zynq中的使用的fpga是中低端的Artix和Kintex,定价策略也做了相应调整。IMHO,这个器件的主要目标市场并非现在的主打telecom(约50%营收)。但如果以Zynq器件构建一个异构多核处理器,例如在Zynq的FPGA部分实现2-8个400MHz的PowerPC软核,定价从25美刀起,对目前的多核市场影响会如何?] 2011年3月2日,中国深圳—全球可编程平台领导厂商赛灵思公司(Xilinx, Inc. (NASDAQ:XLNX))宣布推出行业第一个可扩展处理平台 Zynq™ 系列,旨在为视频监视、汽车驾驶员辅助以及工厂自动化等高端嵌入式应用提供所需的处理与计算性能水平。这四款新型器件得到了工具和 IP 提供商生态系统的支持,将完整的 ARM® Cortex™-A9 MPCore 处理器片上系统 (SoC) 与 28nm 低功耗可编程逻辑紧密集成在一起,可以帮助系统架构师和嵌入式软件开发人员扩展、定制、优化系统,并实现系统级的差异化。 安捷伦生命科学部项目负责人 Ralf Schäffer 指出:“10 多年来,我们一直探讨在单芯片上完美集成处理器与 FPGA 的可能性,以降低成本,缩减 PCB 空间。一段时间以来,数家公司进行了此类尝试,但都没有实现真正紧密的高度集成,难以满足我们的目标。然而,随着赛灵思 Zynq-7000 系列的推出,我们长期以来的梦想终于成为了现实。这意味着安捷伦现在能够采用通用代码库以最低的成本和工程开销推出低端、中端、高端等众多不同型号产 品。” Zynq-7000 嵌入式处理平台系列的每款产品均采用带有NEON及双精度浮点引擎的双核 ARM Cortex-A9 MPCore 处理系统,该系统通过硬连线完成了包括L1,L2 缓存、存储器控制器以及常用外设在内的全面集成。该处理系统不仅能在开机时启动并运行各种独立于可编程逻辑的操作系统 (OS),而且还可根据需要配置可编程逻辑。利用这种方法,软件编程模式与全功能的标准 ARM 处理 SoC 毫无二致。 应用开发人员利用可编程逻辑强大的并行处理能力,不仅可以解决多种不同信号处理应用中的大量数据处理问题,而且还能通过实施更多外设来扩展处理系统 的特性。系统和可编程逻辑之间的高带宽 AMBA®-AXI互联能以极低的功耗支持千兆位级数据传输,从而解决了控制、数据、I/O 和存储器之间的常见性能瓶颈问题。 | |
|
(2个打分, 平均:2.50 / 5) |
AVX高级矢量扩展指令集——英特尔Sandy Bridge 处理器分析测试之三
作者 Lucifer | 2011-03-03 21:04 | 类型 专题分析, 芯片技术 | 11条用户评论 »
系列目录 英特尔Sandy Bridge处理器分析测试
原文精简版发布于《计算机世界》2011年第7期,本文为原稿,篇幅略多
AVX高级矢量扩展指令集 计算机世界实验室 盘骏
在上一篇连载中,笔者介绍了Sandy Bridge微架构中对性能有很大影响的几处改进,然而最重要的执行单元的变化没有涉及到,这部分的变化还跟Sandy Bridge新加入的AVX指令集相关。AVX(Advanced Vector Extensions,高级矢量扩展)是X86上重要的指令集改进,不仅仅在于其对性能的明显提升,还在于其对现有X86指令集的多种革新。
强大的性能:256位向量计算
向量就是多个标量的组合,通常意味着SIMD(单指令多数据),就是一个指令同时对多个数据进行处理,达到很大的吞吐量。早期的超级计算机大多都是向量机,而通过随着图形图像、视频、音频等多媒体的流行,PC处理器也开始向量化。X86上最早出现的是1996年的MMX(多媒体扩展)指令集,乃至1999年的SSE(流式SIMD扩展)指令集,分别是64位向量和128位向量,比超级计算机用的要短得多,所以叫做“短向量”。
Sandy Bridge的AVX将向量化宽度扩展到了256位,原有的16个128位XMM寄存器扩充为256位的YMM寄存器,可以同时处理8个单精度浮点数和4个双精度浮点数,在理想情况下,Sandy Bridge的浮点吞吐能力可以达到前代的两倍。目前AVX的256位向量仅支持浮点,不像128位的SSE那样,也能支持整数运算。
Sandy Bridge微架构的所有执行单元都经过了修改以执行256位AVX指令,特别是对于3个运算端口而言。Sandy Bridge微架构并没有直接将所有浮点执行单元扩充到256位宽度,而是采用了一种较为节约晶体管乃至能耗的方法:重用128位的SIMD整数和SIMD浮点路径。
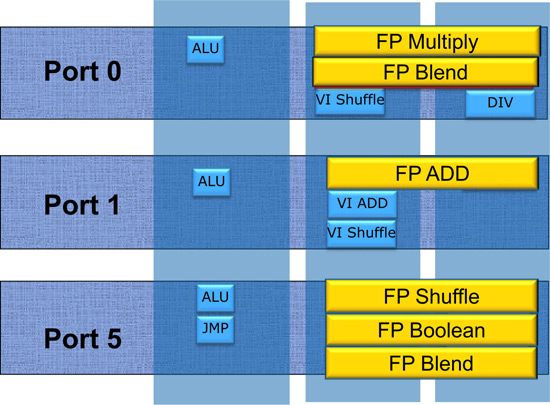
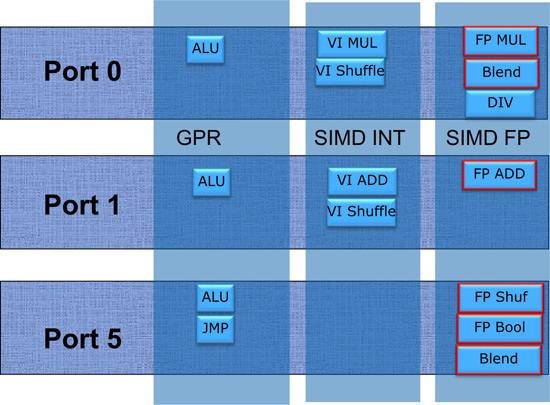 从Nehalem开始的微架构包含了3个运算端口:0、1和5,每个运算端口分为三个功能区域:ALU整数、SIMD INT、SIMD FP,分别执行整数和逻辑运算、SIMD整数和SIMD浮点运算,操作的是32/64位GPR通用寄存器和128位的XMM寄存器。在每一个时钟周期,每个运算端口可以分发一个uop,这个uop可以是三种运算中任意的一种。不同的运算区域可以同时运作,例如在浮点运算进行长耗时计算的时候,仍然使用ALU单元进行通常的整数和逻辑运算。基于执行单元的流水化设计,尽管一些运算耗时比较长,然而每个时钟周期都可以流入新的指令,因此吞吐量也能够得到保证。例外的是除法单元,线路复杂、长耗时并且目前仍未能全流水化。不同运算区域之间的数据传递需要1~2个时钟周期。
 除了AVX带来的性能增强之外,Sandy Bridge还继续增强了AES指令集的性能,提升其吞吐量,此外,SHLD(移位)指令、ADC(进位加)指令和Multiply(64位乘数128位积)运算的性能也都得到了提升,SHLD指令性能提升增强了SHA-1计算能力,ADC吞吐量翻倍提升了大数值运算能力,而最后者提升了现有RSA程序25%的性能。
精简X86指令集
除了明显提升浮点运算性能之外,AVX指令集还是对X86指令集的一个精简。我们知道由于是不定长的CISC指令集,X86指令集可以很容易地进行扩展,每一代处理器都像不要钱似的增加扩展指令集,然而目前的这种通过增加各种Prefix前缀来扩展指令集的方式已经达到了其极限,并且这种方式导致的指令集复杂化和长度增加,导致了执行文件的臃肿和解码器单元的复杂化和低效化。如笔者说过的那样,解码器一直是X86处理器的一个瓶颈所在。
AVX指令集带来了新的操作码编码方式,这种编码方式叫做VEX(Vector Extension),其动机就是压缩各式各样的Prefix前缀,集中到一个比较固定的字段中,缩短指令长度,降低无谓的代码冗余,并且也降低了对解码器的压力,实乃一举多得。VEX编码方式使用了两种VEX Prefix,除了一个字节的字头之外,分别具有1到2个字节的Payload(负载),在这个Payload里面就包括了所有的Prefix的内容,达到了精简指令集的目的。
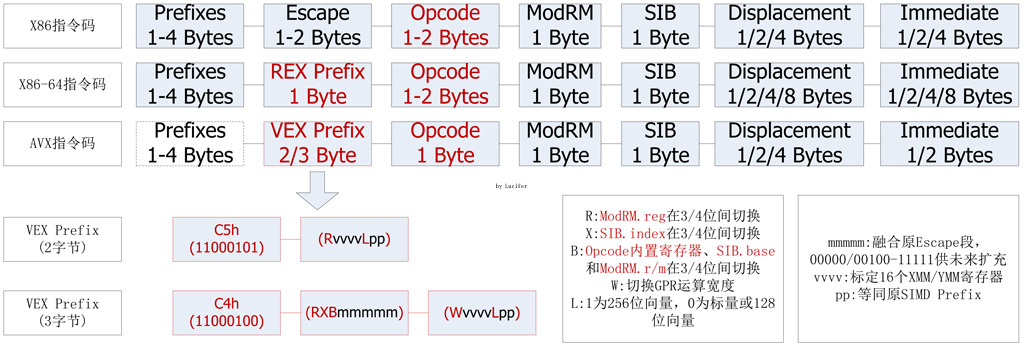 这两种VEX前缀分别是以C5h开头的2字节Prefix和C4h开头的3字节Prefix,前者主要用于包含传统的128位SIMD整数、SIMD浮点运算,后者则主要用来进行新的256位AVX运算以及未来可使用的更多指令集扩展。
VEX前缀包含了X86-64指令使用的REX前缀以及原SSE指令使用的前缀,还融合了普通操作码带有的Escape字段,从某种意义上来说,VEX让CISC的X86指令集往RISC精简指令集靠近了一点,当然,CISC易于扩充、支持复杂灵活的寻址方式的特性依然无损。
如图所示,VEX前缀的RXBW字段包含了原REX前缀的所有功能,pp字段包含了原SIMD指令的所有前缀,在三字节C4h格式的VEX前缀中,mmmmm字段包含了原Escape字段并提供了极大的扩展空间。X86指令总长度不大于15个字节的规定仍然维持不变。
强化X86指令集
基于历史上X86处理器缺乏存储单元的原因,X86指令集属于双操作数的破坏性指令集,例如,指令add ax, bx包含了ax和bx两个操作数,作用是将寄存器ax和bx的数值相加,并保存到寄存器ax当中去,计算结束后,源操作数ax的内容就被计算结果“摧毁”了。如果源操作数的内容在其他运算中还需要用到的话,那么你通常需要保存到堆栈中去,或者保存到主内存中去。实际上X86指令集采用的就是时间换空间的方法。
在传统的仅具有8个通用寄存器的X86处理器上,这种编码方式的使用实属没有办法,同时期具有更多通用寄存器的RISC处理器都采用的是多操作数的非破坏性句法。在应用了Register Renaming寄存器重命名技术之后,X86处理器事实上也具有了很多的寄存器可供使用,如Sandy Bridge内部每个线程具有160个64位整数寄存器,和144个256位浮点寄存器,因此Intel就动起了新的念头,SandyBridge带来的AVX指令集提供了新的3~4操作数的非破坏性句法,在某种程度上,这弥补了X86指令集的体系缺陷。
例如,要实现xmm10 = xmm9 + xmm1,传统X86处理器需要两条指令:
movapps xmm10, xmm9
addpd xmm10, xmm1
在应用AVX指令集新的3操作数格式之后,只需要一条指令就能完成这个功能:
vaddpd xmm10, xmm9, xmm1
而使用4操作数指令的话,下面三条指令可以直接简化为一条:
movaps xmm0, xmm4
movaps xmm1, xmm2
blendvps xmm1, m128
变为:
vblendvps xmm1, xmm2, m128, xmm4
显然,新的指令操作数明显降低了指令的数量,处理器吞吐量得到了提升,代码运行更快速,同时能耗也降低了。
除了对指令集体系的增强之外,AVX指令集还强化了访存不对齐时的性能。传统的指令集当进行不对齐内存访问(unaligned memory access)的时候会需要较长的时钟周期,甚至会有惩罚性延时,极大地降低速度。而在AVX指令集中,各种运算和访存指令现在降低了访存不对齐的延迟损失,在某些情况下甚至能达到和对齐访问一致的性能,显得更加灵活。
X86指令集:不断进化
CISC指令集的思想就是用复杂的硬件来完成尽可能多的工作,RISC则是使用尽量少的指令并通过复杂的程序来完成同样的功能。每一代的X86指令集,都会对不同的应用增加新的指令集,这些指令集能高效地处理对应的应用,例如,上一代Westmere处理器的AES-NI就对加密运算具有非凡的加速比。同样,在AVX指令中也增加了不少浮点运算指令,提升了多种运算的性能。
Sandy Bridge新加入的AVX指令集让X86从128位提升到256位向量运算,大幅度提升了性能,此外,AVX精简了X86指令集的设计,并弥补了破坏性句法的体系缺陷,可以说是一个非常重要的改进。需要注意的是,AVX指令集带来了新的处理器状态和更宽的寄存器宽度,因此需要操作系统的支持才能正常运作,如,Linux Kernel 2.6.30以及Windows 7/Server 2008 R2 SP1版本才能支持。关于Sandy Bridge的微架构就介绍到这里,下回笔者将介绍Sandy Bridge的架构,这部分的变化也非常大,请等继续分解。
| |
|
(2个打分, 平均:5.00 / 5) |

ISSCC2011:全球速度最快处理器
作者 interlaken | 2011-03-01 08:15 | 类型 弯曲推荐, 芯片技术, 行业动感 | 11条用户评论 »
|
去年的ISSCC2010,弯友老刘推荐了IBM的16核网络处理器-wire-speed。 今年的ISSCC 2011结束了,IBM再次介绍了号称全球速度最快处理器z196。http://www.miracd.com/ISSCC2011/WebAP/monday.htm。IT168和维基上都有对这颗芯片的介绍,z196处理器是四核芯片,速度是创纪录的5.2GHz。在512平方毫米的面积上包含了14亿个晶体管。 除了IBM,Intel和AMD外,中科院也秀了龙芯 Godson-3B。 下面这篇网上的报道较为详尽总结了Enterprise Processors & Components分会。 在“ISSCC 2011”Session 4“Enterprise Processors & Components”的分科会上,汇集了有关服务器和超级计算机用高端处理器的技术报告。IBM就“zEnterprise”处理器、英特尔就 Westmere-EX Xeon处理器和安腾处理器Poulson、AMD就Bulldozer处理器内核等纷纷发表了论文。中国科学院也发表了中国在该领域的首款 Godson-3B处理器。整个分科会成为受人注目处理器的技术秀。 从高性能数字领域的另一分科会Session 15“High-Performance SoCs & Components”的论文发表可以看出:个人电脑用处理器方面已出现减少内核数量而集成GPU和周边电路的趋势,但服务器用处理器还是在通过增加内核数量和内存容量来提高集成度。论文编号4.3为英特尔的Westmere-EX Xeon处理器,内置了迄今为止最多的10个内核。另外,论文编号4.8为Poulson处理器,内置了迄今为止最多的31亿个晶体管和合计超过54MB 的缓存。这两款处理器都以32nm工艺制造。另外,论文中指出,Poulson处理器在同一芯片内利用工艺差异制成了慢速内核和快速内核,因此如果每个内核分别独立优化工作电压和频率,便能在不增加耗电量的前提下将性能提高5%。英特尔在上届ISSCC上通过80内核的超多核芯片发表了该技术,不过8内核左右的多核处理器也显示出了该技术的有效性。 另外,英特尔在2009年的ISSCC上发布的Nehalem处理器群中取消了动态电路而采用了全静态设计,而此次的Poulson处理器为削减耗电量,对采用动态电路依然不积极。另一方面,论文编号4.1和4.2是IBM的zEnterprise处理器,其为提高工作频率,在处于关键路径上的缓冲比特判定电路中采用了动态电路。zEnterprize处理器的工作频率方面,45nm工艺为5.2GHz,在产品芯片中首次超过了5GHz。另外,论文编号4.5和4.6是AMD的Bulldozer处理器内核,其为提高集成度采用了动态电路,目的与前面的处理器不同。包括2MB的L2缓存在内的两内核模块的面积方面,32nm工艺为30.9mm2。其在权衡性能和面积之后进行的设计,例如指令解码前的电路和浮点单元(FPU)由两内核共享,并把数据缓存(每个内核)定为16KB等。即使两内核共享电路,性能也只降低了10%。 论文编号4.4是中国科学院的Godson-3B处理器,中国科学院强调了其电力效率较高。集成了8个扩展了x86模拟指令和矢量指令的MIPS处理器内核。65nm工艺的工作频率为1.05GHz,通过追加矢量指令,在耗电40W时实现了高达128GFLOPS的峰值性能。Godson处理器设想用于从嵌入用途到个人电脑乃至超级计算机的广泛用途。此项目为耗资50~100亿美元的16个国家级开发项目之一,可谓举中国全国之力开发而成。 最近5年来,高性能处理器的耗电量最大可降至一百几十瓦(W)左右,虽是高性能处理器的会议,但论文发表的核心之一却是低功耗技术。此次还发表了工艺技术、电路、微架构及设计方法等多种低功耗技术,有观点认为要将降低的耗电量积极用于提高包括单线程性能在内的处理器的速度,这种思考方式的变化耐人寻味。 | |
|
(没有打分) |
弯曲评论荣誉推荐–Nehalem Mem子系统测试
作者 陈怀临 | 2011-02-27 19:39 | 类型 芯片技术 | 3条用户评论 »
