




Intel研发的八旗主力分布
作者 陈怀临 | 2011-02-27 19:26 | 类型 芯片技术, 行业动感 | 30条用户评论 »
|
最近Intel的Sandy Bridge的芯片组的出事,爱Intel的摇头;恨的人拍掌。。。 前段时间,弯曲上也谈一下Intel的ATOM的前世今生。。。似乎痛骂Austin的人不少。。。 读者要问了。Intel研发的工兵队伍是如何布局的?否则,这样下去,哪天王大师的WLRU based General CPU流产,sorry,流片了,Intel就歇了。我大宋N夜之间灭了Intel,我估计王大师就是今日的岳飞了。。。 Intel的研发其实分3个阵列。基本上分为第一梯队(Tier 1),第二梯队(Tier 2)和边缘团队(第三梯队(Tier 3)。。。;类似与当年入关时横扫我大明的满清八旗【吴三桂其实无罪;通读历史的感觉是农民起义是胡扯。李自成才是我大汉的罪魁祸首。我是吴三桂我也借兵。】 通常而言,Ti的人看不起T(i+m)的人。(m=1,2)。 从首席的八卦程度,Intel的八旗是这个这个样子的。。。 正黄:Oregon研发中心【Intel最大的研发基地,Nehalem和Westmere的主力】 另外,一家之言,错误之处,多多涵养。。。。。。 | |
   (3个打分, 平均:3.67 / 5) (3个打分, 平均:3.67 / 5) |
Juniper发布Q-Fabric
作者 陈怀临 | 2011-02-24 19:04 | 类型 芯片技术, 行业动感, 通讯产品 | 30条用户评论 »
|
【陈怀临注:Pradeep基本上是印度人在硅谷的领袖。很难想象没有Pradeep的Juniper,analogous to Steve Jobs of Apple。我对Juniper的理解就是:Juniper是一个以芯片为主导的MPLS公司。 帝国主义其实从来不是纸老虎。那是毛润之骗老百姓的话。。。】
| |
|
(没有打分) |

弯曲评论荣誉推荐:Intel Westmere-EP评测
作者 陈怀临 | 2011-02-14 21:28 | 类型 芯片技术, 行业动感 | 2条用户评论 »

WLRU专利的非专业解析
作者 kevint | 2011-02-12 21:45 | 类型 弯曲推荐, 芯片技术, 行业动感 | 68条用户评论 »
WLRU专利非专业解析
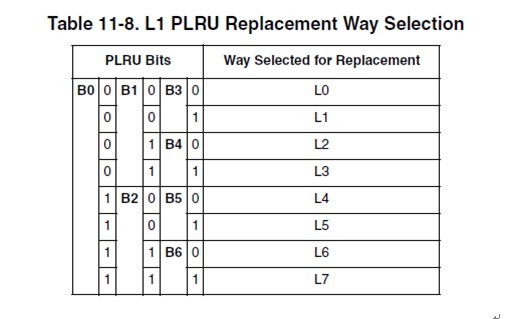
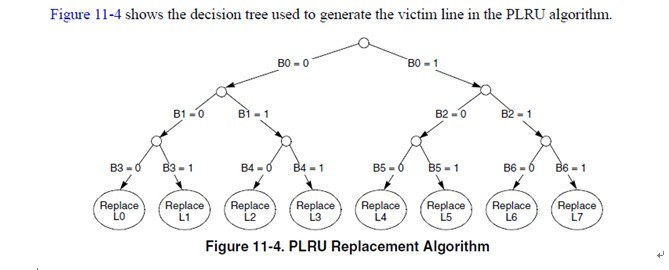
11.6.2.1 PLRU Replacement Block replacement is performed using a binary decision tree, PLRU algorithm. There is an identifying bit for each cache way, L[0–7]. There are seven PLRU bits, B[0–6] for each set in the cache to determine the line to be cast out (replacement victim). The PLRU bits are updated when a new line is allocated or replaced and when there is a hit in the set. This algorithm prioritizes the replacement of invalid entries over valid ones (starting with way 0). Otherwise, if all ways are valid, one is selected for replacement according to the PLRU bit encodings shown in Table 11-8.
注意,红色的字体是与王大师的WLRU关键的不同点。在e500的cache中,选择victim是在set select中。每一个set,有7个bit用来做cacheline的weight。
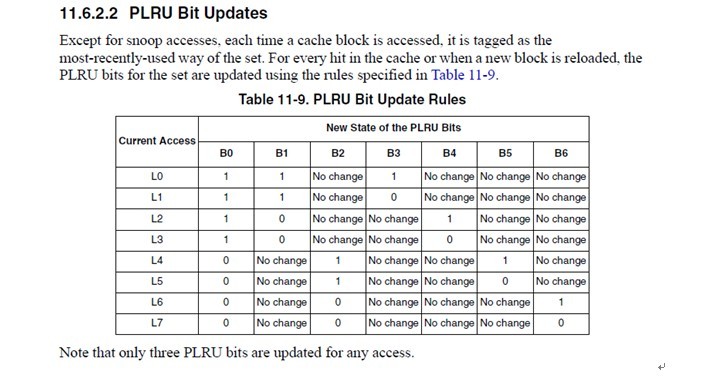
这个真值表简单明了,我就不多解释了。 所以当某个line hit的时候,或者当某个line refill到达的时候(其实line refill到达的时候也相当于hit after miss),cache logic根据这个表,更新cache set的这几个bit。 cachemiss的时候,再根据b[0:6]找出一个line换出去就完事了。 一般CPU的PLRU就是这么做了。当然,也可以像某些MIPS那样,random选一个完事。 7.王大师的WLRU是怎么做的
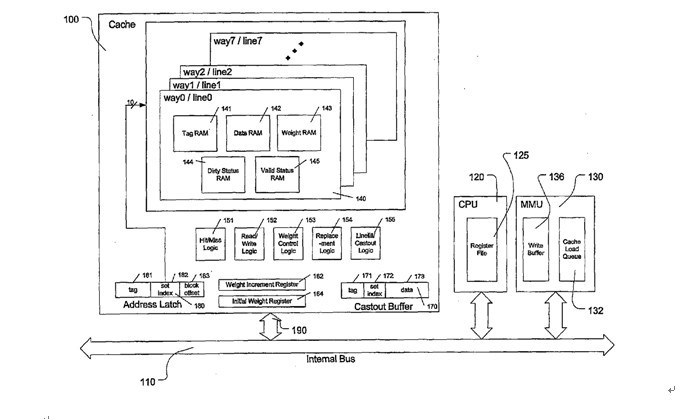
这是王大师专利中的系统框图。 注意一点,就是一个set中,每个cacheline都有一个weight ram。这点与e500不同。e500的victim select是在set select选中后,根据PLRU[0:6]选中一个line。如果WLRU 的weight ram存在每一个line中,那么每一个line都要参与weight的比较,才能算出最终的victim line。这样无疑会增加cache lookup的延迟。 王大师是这么描述的
WLRU的配置 WLRU用“i-r-b”作为weight的算法的参数 i,increment,cache hit后weight的步进。 r,upper limit,weight的上限 b,初始weight。 如i64r128b2。cache hit一次,weight增长64,最大增长到128. cacheline初始weight 为2. 每当cachemiss一次,weight减一。
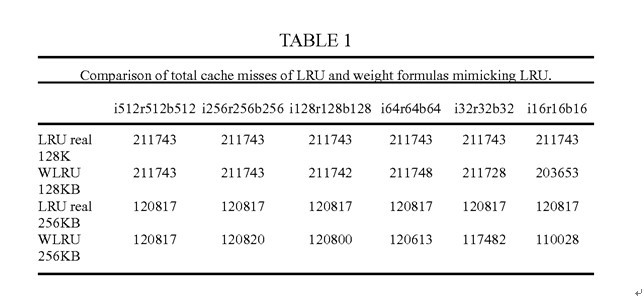
这是王大师在专利中给出的数据。与真LRU比较,证明自己的算法在r比较大的时候,是可以接近真LRU的效果。 这里王大师又搅了一次混水。证明自己的算法在某种情况下可以达到美好的理论值,但是没有详细做横向比较,比如其他LRU算法,跑同样的测试,能达到什么效果。
也没说跑的什么测试例,最后扔下这么一句话,横向比较算做完了。 更尴尬的一点,抛开这个“more than 30% fewer”句型,cache miss rate低30%以上,让人如何理解。比如原先PLRU的miss rate是1%。你低30%。那你就是0.7%。假如PLRU hitrate是99%,WLRU的hitrate就是99.3%。群众关心的综合的performance boost是多少。没说。 回到现实,看看王大师的weight ram实现的成本如何。拿专利中r256为例吧 如果upper limit 是256,那么每个line 要8个bit做weight ram。按照1valid+1dirty+19tag+256data=277bit。增加8个bit,大概增加8/277=2.8%的面积。这个数据,可能就是王大师所说的“WLRU相比于Pseudo-LRU(目前广泛使用的LRU的低代价实现变种)只多2%的晶体管,电路成本的增加微不足道。”的来源。 虽然费料不多,但是这里费时才是关键的。 每一个set要多一个8in 8bit的比较器做weight比较。这个就比较要命了。 另外,当某一个line hit的时候,需要increase它的weight。需要读出weight increment register,再从ram读出当前weight,加起来,比较是否超过了upper limit,如果没超过,再写回weight ram去。cache miss的时候,还要decrease所有line的weight。8条cacheline啊,这些都是要r-m-w的。这cache access的latency。我敲这些字都觉得罗嗦。 所以,这个WLRU做L1 CACHE是没戏了。这点也跟王大师的宣传类似,从哪搞个core,外面挂个WLRU的L2,大力丸子场就算搭起来了。 总之,理论基础铺垫完了。结论也只说能降低“miss rate”. 至于performance boost rate,没提。 8.回到现实—CWLRU 王大师也应该知道,r256,r128的模型只能在论文里做,现实是做不出来的。拿什么救场了。CompactWLRU横空出世啦。 CWLRU使用2bit做weight,并且在每一个cache set增加了一个reference counter。当line hit的时候,weight加1。miss的时候,先decrease reference counter,当reference counter到达某一个threshold的时候,再decrease 所有cacheline 的weight。 weight ram正常情况只有+1和-1的操作,所以可以用counter ram做。不用再读那个weight increment register了。 decrease 1的操作也用reference counter做了聚合。 所以,这个CWLRU,是对上面那一系列繁琐的操作做了一个简化。reference counter越大,weight采样的偏差就越大。 正常人应该看出来,这个CWLRU是非常狗屎的一个近似。。
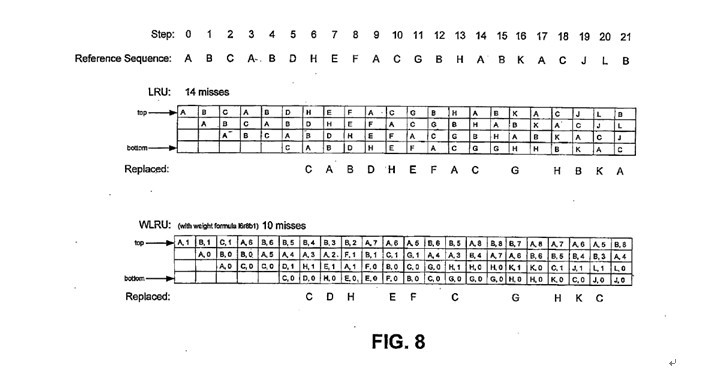
无奈王大师再次扔了一个丸子出来。。。一句话,把这个狗屎的近似算法扶正了。仍旧没有数据支持。 不管是WLRU还是CWLRU,最最要命的一点,就是有几个软件配置的寄存器。这样一来cache对系统不在透明,至少kernel developer在cpu init的时候需要配这个玩意。配多少?难道真的要application aware? 9.专利是需要证明有实际价值才能通过的。WLRU如何证明自己专利是有价值的呢? 一切答案尽在FIGURE8.
我对王大师在弯曲的第一次回复就说过,如果知道cache的组织结构,随便写个程序,让cache hitrate提高/降低10倍,都不是什么难事。 注意step0到step9. 真LRU的情况下,在step3-step7这5个step中,A没有被reference,所以被置换出去了。 而在WLRU中,因为 恰好step0中A被reference了,在step7时所以A的weight更高,没有被置换出去。 王大师在这里客串了一把刘谦,通过自己精心准备的道具(reference sequence)。证明了在WLRU在4way cache上面,miss rate是真LRU的70%。 这里算手下留情了。构造个狠一点的序列,估计真LRU还要惨。 说到这里,各位看官应该大致明白是怎么回事了吧。 王大师说这几年一直在忙着准备测试数据,估计也还是在享受通过构造各种序列降低cache missrate的快感中把。 10.捅破那层窗户纸—WLRU的本质 写这篇文章的时候,我也在思考。WLRU的价值在哪里。个人观点: 其实,这东西就是想是让那些 使用次数少的数据尽量少占用cache。这也是众多PLRU算法的初衷。标准PLRU算法在开销和预测方面选择了折中。而WLRU加入weight ram就让cache有了更大的记忆,weight ram越大,记忆的时间越长,理论预测的就越准确。当然开销也越大。 所以,这个WLRU并没有什么神秘,如首席所说,Jonh Hannessy还没老年痴呆。 前面说了,就算最简单的CWLRU,仍旧过于复杂。不可能做L1 CACHE。 CWLRU能否应用在L2 CACHE上?我想理论上不是没有可能的。不过我不是做IC的,不知道如何实现。另外,专利中的系统框图与ppc,intel的系统框图比起来基本就是小学生的家庭作业。从他的图看,cache是直接physical index, physical tag的。一般也是L2 cache才这么干。 同时,这个东西编译器应该也可以做一些工作,虽然肯定没有运行时预测的准确。但是,应该也是可以做一些工作的。什么时候编译器能够加上cacheline_size, way_number等参数?是不是也是首席说的cache aware application的一种实现呢。 不管怎么样,cache只是整个CPU系统中的一个子系统,CPU又是整个计算系统中的一个子系统,cache的优化,对于系统的加速比是多少?是否有王大师大力丸子场中描述的那般神奇可以“干掉intel”呢? 11.结语 我与公司一个做cache controller的engineer聊了一下,大致对话如下 我:对cache replacement algorithm有没有研究。 他:一般都用PLRU啊。 我:网上有个人说发明了一种cache replacement algorithm,号称miss rate降低了30%-50。能灭掉intel。 他:你给我一个100%hit的cache我也灭不掉intel。哈哈(此人以前做某主流高性能CPU) 我:他就是这么说的。现在正招商引资呢 他:回国忽悠吧。这边估计是没戏了 我:恩,已经回去了。 | |
|
(14个打分, 平均:4.00 / 5) |



弯曲评论荣誉推荐:三种Nehalem内存配置测试
作者 陈怀临 | 2011-02-10 21:49 | 类型 芯片技术 | 4条用户评论 »

芯片是怎么炼成的。。。
作者 陈怀临 | 2011-02-07 16:44 | 类型 芯片技术 | 2条用户评论 »
王大师的WLRU 。博士论文
作者 陈怀临 | 2011-02-06 17:25 | 类型 科技普及, 芯片技术, 行业动感 | 35条用户评论 »
|
【陈怀临注:说良心话,说王大师啥也不懂是偏激。说其骗人也不是事实。好歹专利和几百页的洋文还是满花功夫的。另外,从文献的列表,感觉王大师还是满有学问的。我对王大师印象的改变来自小样把Xiaodong Zhang的一个LRU的算法列在文献中了。顿时感觉小王不是骗子,而是书呆子:-)。我个人感觉,其这个WLRU算法还是有一定的水平,但为了忽悠国内的政府产业基地,估计有点语不惊人死不休。。。通常而言,一个WLRU算法很难被用来做通用CPU。但我感觉用在高端的,专门用在某个产业的NPU,带Cache的ASIC,例如Cisco的QFP,Juniper的Trio,华为的啥Solar芯片 blah blah,还是比较靠谱一些。例如,卖专利,license fee。。。希望小王,或者老王成功。有需要帮助的地方,请说话。。。:-)。另外,在弯曲评论,有许多国内外大通信厂商的同学。小王应该在这里多阐述你的算法。。。首先要建立credit。才能办事。没有credit;很难成事。】 | |
|
(4个打分, 平均:4.00 / 5) |

展讯 。40纳米手机芯片
作者 陈怀临 | 2011-02-01 18:42 | 类型 芯片技术 | 5条用户评论 »
|
【陈怀临注:几天没有follow up SPRD的股票。今天一看,22美金多了。狂喜之余,很纳闷,也算是知情人呀。没事也在gtalk上与SPRD的VP套套瓷,没感觉有什么重要的棋在下呀。。。逛逛土豆,想挖掘点科技新闻,才恍然大悟。。。:全球首款40纳米TD-HSPA/TD-SCDMA多模通信芯片SC8800G。】 | |
|
(没有打分) |
细节决定成败 。Intel 。Sandy Bridge
作者 陈怀临 | 2011-02-01 08:29 | 类型 芯片技术 | 72条用户评论 »
Sandy Bridge微架构的革新——英特尔Sandy Bridge 处理器分析测试之二
作者 Lucifer | 2011-01-27 07:07 | 类型 专题分析, 芯片技术 | 23条用户评论 »
系列目录 英特尔Sandy Bridge处理器分析测试
原文发布于《计算机世界》2011年第4期 Sandy Bridge微架构的革新 ——英特尔Sandy Bridge 处理器分析测试之二 计算机世界实验室 盘骏 上文中笔者介绍了Nehalem微架构中存在的一些问题, 到了Sandy Bridge 这一代,这些问题还存在吗? 下面我们就来详细解析Sandy Bridge 的微架构,并介绍相对于Nehalem 微架构的改进。
 前端:分支预测和微指令缓存
分支预测、指令拾取、预解码以及解码这几个部件组成了处理器微架构的Front-End 前端部分。在Nehalem 微架构中,指令拾取和预解码存在问题,在一些情况下会导致指令吞吐量过低,因此其前端是整个流水线当中最容易成为瓶颈的阶段。Sandy Bridge没有直接在指令拾取和预解码阶段进行改动,而是对整个前端部分进行了重新设计,通过革新的分支预测单元以及在解码阶段加入一个新的部件来增强整个前端部分的输出能力,同样达到了消除瓶颈的目的。
处理器的前端从L1 I-Cache拾取指令,在指令拾取单元没有什么变化的情况下,Sandy Bridge 的L1 I-Cache 也有了些改进,提升了大型应用程序下的性能。首先,它从Nehalem 的4 路组关联提升到了8 路组关联,从而降低了CacheLine 碰撞的几率, 降低了页面冲突; 其次,L1 I-Cache 对应的L1 ITLB 也略微扩大,2M/4MB 对应的TLB 表项从Nehalem 的7+7 提升到了8+8(对每一个硬件线程提供8 个表项),可以覆盖更大的代码地址空间。
分支预测是一个既能提升性能又能降低能耗的做法,成功的分支预测可以避免无谓分支代码执行的性能、功耗损失。Sandy Bridge的分支预测单元在Nehalem的基础上进行了完全的重造。通过对分支表结构的压缩定义,BTB(Branch Target Buffer,分支目标缓存)在同样容量下将保存的分支目标翻番,同样,GBH(Global Branch History,全局分支历史表)也能保存更多、更深的项目,总的来说,分支预测准确率将会进一步提升。
前端变化中作用更明显的解码器旁边加入的uop cache(微指令缓存),这个部件和NetBurst 微架构的Trace Cache 作用非常相似,不过却是经过了更多的调整和优化, 并且更加简洁。uop cache 保存了已经解码的微指令,并且更加接近处理器的后端,因此也可以被称为L0 I-Cache。根据英特尔的说法,通常的应用当中其命中率可以达到80%, 在命中这个缓存之后,包括复杂的解码器在内的其它前端部件可以关闭以节约能源,而由uop cache 本身输出指令。这个设计可以很明显地降指令拾取低延迟乃至分支惩罚,让前端可以在更多的时间内处于持续输出4 uop/cycle 的状态,这很大程度消除了Nehalem 前端的瓶颈。
 后端:物理寄存器文件架构
Front-End 前端紧接着的是Back-End 后端部分,Sandy Bridge在后端部分也有了很大的变化,其中一个变化来自于寄存器文件的变迁。在之前,我们介绍了Nehalem微架构采用的RRF(Retirement Register File,回退寄存器文件)存在的会导致寄存器读停顿的问题,Sandy Bridge 通过采用了PRF(Physical Register File,物理寄存器文件)结构来消除了这个问题,和前面的uop cache 一样,PRF 的设计也是从NetBurst 架构借鉴而来。几乎所有的高性能处理器都采用了PRF 的方式。
在Nehalem 微架构当中,ROB(ReOrder Buffer, 重排序缓存)顺序保存了所有uop 及其所有的重命名寄存器的数据和状态,架构寄存器则保存在RRF 当中。在SandyBridge 的PRF 上,ROB 不再保存重命名寄存器的数据,取而代之的是保存多个指向PRF 的指针,架构寄存器包含在RRF 当中,通过状态位来标识。
物理寄存器文件有什么好处?首先,它消除了旧有的寄存器读停顿造成的瓶颈,现在它不再受限于RRF 三个读取端口的限制,所有不同寄存器的内容都可以同时进行读取, 不会再引起流水线停顿。其次,物理寄存器文件消除了寄存器间数据的复制和移动,而只需要更改指针的指向即可,这节约了大量的数据移动能耗, 特别是在Sandy Bridge 的AVX 指令集支持更多的操作数以及支持的最大寄存器宽度翻倍的情况下。最后,ROB 从保存数据变成保存指针导致了结构上的简化, 从而增大了ROB 的容量,进一步提升了处理器乱序执行的性能。
Sandy Bridge 的ROB 从Nehalem 的128 项提升到了168项,PRF 物理寄存器文件包含了两个部分:每项64bit 、一共160项目的整数寄存器文件和每项256bit 、一共144 项目的浮点寄存器文件,并且PRF 是每个硬件线程各自一份。在Sandy Bridge架构当中,还增加了一个硬件监测机构,在使用SAVE/RESTORE指令进行线程切换或者虚拟机切换的时候,可以仅仅恢复/ 保存线程所使用到的寄存器,而不是恢复/ 保存所有的架构寄存器,从而节约了上下文切换的时间,这可以提升处理器运行大量线程和多个虚拟机的能力。
 后端:存取单元
微指令经过重命名阶段和读取PRF 数据之后进入Reservation Station 保留站, 通过统一的调度器安排发射到6 个不同的执行单元之中。Sandy Bridge 的Reservation Station 容量从Nehalem 的36 项目提升到了54 项目,增加了50%,乱序执行窗口的扩大可以提升处理器的乱序执行能力。
Sandy Bridge 的执行单元也有了很大的改进。执行单元包括计算单元以及存取单元,这两个都变化甚大,不过这里我们先介绍存取单元的变化,因为之前介绍过Nehalem微架构在这方面是个潜在的瓶颈。计算单元的改进留到下一篇文章中再介绍。
Sandy Bridge 架构和Nehalem一样具有3 个存取端口,Store 端口维持不变而Load 端口的数量提升到了两个,并且这两个Load 端口的AGU 地址生成单元均能生成Store 操作使用的地址。Load 端口翻番在某种程度上是为了适应Sandy Bridge 处理器新增的AVX指令集带来的256 位计算能力,因为每个Load 端口的宽度是128 位。然而,现有的各种应用也可以立即从中获益, 因为Nehalem 微架构的Load 端口仅占所有执行单口的1/6, 而Load 操作通常可以占据uop 当中的约1/3。Sandy Bridge的双Load 端口可以每个时钟周期进行两个128 位Load 操作,消除了上一代的瓶颈,工作起来也更为灵活。
和Load/Store 单元连接的MOB(Memory Ordering Buffer, 内存排序缓存) 也得到了增强,MOB和前面的ROB 一起属于将乱序执行和顺序回退连接起来的重要部件。在MOB 当中,Load 缓存从Nehalem 的48 项目提升到了64 项目, 提升幅度为33%,Store 缓存从32 项目略微提升到了36 项目。
Sandy Bridge 的MOB 一共可以容纳100 个访存操作,这些数据操作均为256 位宽度。和Load 能力翻倍配对的是L1 D-Cache 的增强,它的带宽提升到了48 字节, 也就是384 位, 比以往的32 字节提升了50%,以同时支持两个128 位的Load 和一个128位的Store 操作。搭配的L1 DTLB据说也有所改进, 增加了4 个支持1GB 页面的项目,以进一部消除Nehalem 微架构在面对海量内存应用下的性能问题,这4 个大页面DTLB 项目应该是全关联的,其它的L1 DTLB 则应该维持4 路关联不变。
在L2 Cache 方面,Sandy Bridge 相对Nehalem 没有太大的变化。
 可以看到, 通过将Nehalem微架构和NetBurst 微架构进行融合, 引入NetBurst 上的微指令缓存和物理寄存器文件架构,并改进Load/Store 单元和L1 D-Cache带宽设计,Sandy Bridge 消除了上一代Nehalem 微架构存在的比较明显的三个瓶颈,还顺带获得了更多的附加增益。Sandy Bridge在整个流水线的方方面面都得到了改进,然而还有一个很重要的部分没有被提及: 运算单元, 这个部分的变化和Sandy Bridge 引入的AVX 指令集紧密联系,请看下回继续分解。
| |
|
(4个打分, 平均:5.00 / 5) |
