




闲话Juniper的PTX和分组光传输系统P-OTS
作者 高飞 | 2011-06-19 10:10 | 类型 行业动感 | Comments Off
|
Juniper的技术和战略考虑有二:技术上,Juniper相信(其实就是CTO同学相信),基于分组处理的方法更适用于未来网络的突发性和难于预测的业务流量。战略上,Verizon一直希望在核心层用二层的交换机替换掉昂贵的三层核心路由器(端口);在近几年的光网络会议上Verizon一直在大力推动这个理念。 在众多北美运营商中,Verizon一贯比较乐于把自己的需求在业界会议、展会和新闻发布会上大声说出来。Verizon希望的东西是一个long-haul OTP盒子,2011年下半年或者2012年交付,盒子要包括如下关键技术:DWDM,OTN和以太交换,以及Sonet/SDH支持。在40G/100G传输要开始流行的时候,如果得到Verizon的这笔订单,对任何设备商而言,随之而来的潜在市场先机优势都远远大于账面上得到的银子。 PTX一出生,Juniper给其的定位就是一个集成了光传输和IP/MPLS的,傻快傻快的大容量交换机。MPLS处理分组业务,同时利用光传输网络(OTN)来处理电路业务。PTX的切入点是从光网抢夺市场,在运营商升级的时候和阿朗、Ciena、日立、华为抢吃的。 目前阿朗、Ciena和华为都把OTN作为其packet-optical产品的主打宣传点,PTX剑指的就是阿朗1870、Ciena的5400系列和华为OSN8800系列。阿朗和Ciena都出现在Verizon需求信息征询短名单上。这些厂商都从自己的强项光盒子开始发力,逐步加入分组处理功能来满足P-OTS的需求。题外话:从Verizon的需求信息征询看,华为的OSN8800最符合需求,但是华为暂时也最不可能出现在短名单上,原因本文不赘述。 Juniper采取的是相反的策略,从分组处理往下走。Juniper并不以OTN见长,因此PTX的核心定位也不是OTN,而是MPLS,这明显与市场上其他几个哥们的产品不同。从设备上看同样如此,PTX已经具备了强大的MPLS和分组交换能力,但是PTX目前的optical shelf名为OTS1000,实际上是OEM一家德国厂商ADVA Optical Networking (Frankfurt: ADV)的FSP3000。OTS1000目前包括ROADM和DWDM transponder等功能,在软件上由Junos统一管理。未来Juniper也许不会把研发力量花费在这些光组件上,而是转而借Junos宣传其supercore和core的解决方案亮点——统一的软件平台、统一的部件标示来管理路由器、MPLS交换机和光传输部件。 P-OTS博弈最后决胜的兵器显然是一种能natively处理两种业务(MPLS和OTN)的设备。众多厂商心里都对此有规划。只不过当前阶段,从商业的角度考虑,厂商必须考虑自己的技术积累和强项,来决定what comes first,以及如何向市场和客户讲这个故事。Juniper目前的主要客户都还没有对OTN那么急切的要求,因此PTX把OTN功能放后可以理解。但是目前几乎所有的电话公司(同时也几乎都是ISP)几乎都有电路交换的网络,OTN对其支持最好。因此没有OTN,这个故事最终要编圆的难度很大。Cable运营商则是另一种局面。3P时代(不要想歪)的cable运营商更愿意接受纯粹的分组交换核心。从这个意义上说,也许PTX的目标不是从Verizon和AT&T,而是从北美cable运营商那里打开局面;Juniper其实底下一直在和comcast以及时代华纳有线眉来眼去?(注:comcast和时代华纳是北美前两名cable运营商)。 | |
 (没有打分) (没有打分) |

对大宋下一代系统软件架构师的七个期望
作者 陈怀临 | 2011-06-18 17:35 | 类型 弯曲推荐, 研发动态 | 52条用户评论 »
|
有诗云:人之老,其言真;人之去;其行善。 系统软件设计是软件系统的皇冠中的宝石。绚烂美丽。令无数男女痴迷。 在系统软件,特别是通信系统软件的设计上,有没有一些可以提炼的方法论? 今身处幽州(北平),心在大宋。聊聊数语。谈谈我对大宋年轻一代的系统软件工程师的期望。 1。 The Thinner vs. The Thicker 系统软件一定要越细越好;越薄越好。 我在华为做speech的时候,也提到过:能把系统软件做薄,才是一代高手。 最可怕的就是为了做而做。 最高境界是:能不做就不做。 每一行代码,都会成为历史(Legacy);每一份恋情都会成为过去。 工程的事情,就是要简简单单。 内在算法的复杂不代表外在的臃肿。 一个女人,要的是清澈美丽;而非妖娆迷人。 智慧者应该做的是cut;而非单纯的add。 2。 Re-Create vs Re-Search ReCreate是工程之大忌。任何一个问题,必须首先养成良好的科研习惯: 如果有,拿来主义基础上的改良主义就是最好的。重复发明已经发明了的算法,模型是兵家之大忌。 3。 Qualitative vs Quantitative 自然科学在中国的错失是我们大宋百年之痛之根本之一 定性和定量分析的有机结合,是成为一个优秀的系统软件架构师的基本素养。 只有定性分析的胶片,是研发之大忌。 一定要养成能case study,算法分析的良好工作习惯。 要的是数据说话;不要的是框架忽悠。 大宋某公司特别喜欢玩一个词汇:技术断裂点。还有一些:领先世界产品的优势点。 这基本上是胡扯。或者从大样本的角度,是胡扯。是文革作风。是党八股。 作为一个工程设计人员,不要羞于Feature Parity。学习和模仿美军,伪军的东西,是提高自己的最佳方法。不要上来就是什么断裂点。 邓公稼先都说:我们这几代人要做的是使得国家不要差距加大。 我们这2,3代人能做的是:Follow。领先基本上不存在现实。 这其中,最大的问题不是工程,而是教育的落后。教育的落后使得我们不存在成为一个高科技大国的基础yet。 所以,不要有强迫症,没事玩断裂点。跟上并略微有改良就好。 这就好比,明明不是AV明星,非要玩AV明星的动作。。。受罪。 请把创新留给90后和00后吧。。。 5。 Semi-Optimal Optimization vs Full-Optimal Optimization 工程上,没有最好的算法;只有最好的折衷。 不要过分追求最佳算法。要能把握算法带来的时间和空间上代价的折衷。更为重要的是,在工程上,如果出了问题,调试,调优和定位带来的代价。否则,能解决问题的算法,就是好算法。 6。 Application vs System 系统是为应用服务的。 男人的钱是为你爱的女人而挣的。 做系统不能玩意淫。不能为做系统而做系统。 一切要为人民服务,为应用服务。 只有人民的需要,才是系统软件的需要。 “爱系统软件就是爱人民。是等价的”。这是愚弄人民。 不能本末倒置。 应用和系统是相通的。你能写汇编,也能写object-C。都是逻辑的表达而已。 7。 Proprietary vs Open Source 拿来主义,没人反对。也需要提倡。但如何贡献和反馈给社区,这是每一个大宋系统软件工程师应该反思的。知识共享不仅仅是一个方法论,也应该是一种精神家园。 天天信息安全,什么都藏着,躲着,非一代天骄之所为。 成大事者,必有大胸怀。公司也好;个人也罢。 | |
  (25个打分, 平均:4.72 / 5) (25个打分, 平均:4.72 / 5) |
像使用云计算一样使用电力
作者 libing | 2011-06-17 08:53 | 类型 云计算, 行业动感 | 127条用户评论 »
|
这是云计算的时代,各种展会上,大大的标题是“像使用电力一样使用云计算”。如果闲聊时不能扯上两句云,你都不好意思开口! 人人腾云驾雾,难免审美疲劳。这个时候必须独辟蹊径,才能抓住注意力,一举成为聚会的核心。湾友们下次吹牛打屁时,不妨换个思路,将开场白变成“像使用云计算一样使用电力”,保准一击制胜,收获青睐者崇拜的目光! 这个故事的来由是这样滴~~干冰放雾~~~ #################朦胧的昏割线####################### Cisco最近同Samsung联合整了一个虚拟桌面显示器,这个显示器显示图像估计稀松平常,其稀奇的地方在于显示器本身无需电线,其电力由网线提供,这种形式特别适用于快速部署的虚拟桌面环境。传统的虚拟桌面虽然解决了终端的维护,但仍然需要电力线给显示器供电,使用了这套方案之后,连显示器都无需电源插座了。 实际上,通过网线供电是个很成熟的方案,既所谓的Power Over Ethernet。但之前的PoE产品单端口输出功耗一般在15瓦左右,比较新的基于802.3at标准的交换机能达到30瓦,仅仅用来接入IP电话或WIFI无线基站。这次Cisco在主力接入交换机Catalyst 4500平台上推出的板卡,单端口输出功率能摸高到60瓦,且支持IEEE 802.3az智能电源功耗标准,Cisco将其命名为UPoE—Universal Power Over Ethernet。 这样高的功率不但能驱动显示器,还能带动楼层内的控制系统,甚至小型视频会议终端。通过UPoE方式,网络不但能向终端输出数据中心的计算资源,且连电力都一并输送了,今后做系统部署时,楼层电话线和电力线都大大缩减,大部分终端都是一根网线搞定, 真正是“像使用云计算一样使用电力”。 ####################我也是昏割线######################## 顺着这个话题,湾友们还可作此引申: 软件平台的搭建仅仅是云计算万里长征的第一步,云计算给IT带来的冲击更深刻地体现在业务流程的颠覆性改变上,很多时候不是技术实现不了,而是制度跟不上。当所有的工作都集中到数据中心后,怎样保证资源高效、安全地地传递到用户手中,这将是下一步的挑战,这些挑战可能但不仅仅包括: 1)瘦终端的性价比 2)用户的安全登录 3)终端用户的漫游体验 4)瘦终端的形式 。。。。 要解决这些问题,网络在其中扮演了重要的角色,但仅仅完善网络还远远不够,还需要将客户的整个IT制度都根据云计算的特性进行重新规划。比如,有了UPoE之后,在做楼层布线时是否还需要那么多电源插头呢?现在很多大楼在做弱电装修时仍默认布设电话线缆,完全没有考虑今后使用VoIP的可能,类似的情况如果不能解决,也必将成为推广云计算的障碍。 | |
|
(2个打分, 平均:5.00 / 5) |
工具箱
本文链接 |
|
打印此页 | 127条用户评论 »
《云计算核心技术剖析》迷你书连载三 – 云计算的商业模式
作者 吴朱华 | 2011-06-16 07:32 | 类型 云计算, 行业动感 | 5条用户评论 »
|
本书快重印了,谢谢大家的支持,网上购买通道有当当和China-Pub。
在云计算的商业模式方面,最主流的是本书开头提到的“电厂”模式。除了这个模式之外,“超市”模式也受到业界一部分人的推崇。下面将深入分析和比较这两种模式,其中将涉及它们的用户体验、成本和挑战等,并在本节末尾与大家探讨在商业模式方面云计算的未来。
12.2.1 “超市”模式当我们进入超市时,里面有琳琅满目的商品任凭我们挑选,不管是自制的,还是来自第三方供应商的,我们都能非常方便地凑齐生活所需要的必需品。同时由于超市运营规模普遍较大,它在产品售价和运营成本上面都有优势。而且超市并不是只此一家,如果不满意这家的商品和服务,完全可以选择另外一家,虽然之前的积分等很难转移或者之前超市有我们需要的专供商品。同时,当我们需要更安全、更值得信任的食物或者其他更定制化的产品时,完全可以自己种植、生产或者到我们所信任的超市购买。 简单地说,“超市”模式是一个平台化的概念。云计算厂商主要提供一个云平台,在这个平台上提供丰富的信息服务供用户选择。无论是来自平台商的还是第三方的信息服务,都可以按需购买,而且价格一般比自建优惠。如果此云供应商所提供的服务令我们不满意,我们完全可以选择其他云供应商,但是整个迁移流程会比较复杂。虽然“超市”模式主要体现为公有云,但是当用户对安全极为关注,或者需要定制化,或者希望完整控制数据的时候,用户还可以通过和云计算厂商合作来将云平台复制或者部分迁入用户的数据中心内来实现私用云或者混合云。 现在已经有很多IT供应商提供了类似“超市”模式的云平台,比如Amazon的AWS、微软的Windows Azure 平台和IBM的Blue Cloud等,虽然这些云平台都还处于成长期,但是可以预见,将来这些云平台应该能像超市那样提供丰富的服务。“超市”模式的用户体验使用成本和面临的挑战可以概括如下。 1. 用户体验
2. 成本
3. 挑战如果要实现“超市”模式,需要解决哪些挑战呢? 在安全方面,主要包括以下6点。
在服务质量方面,主要有下面两点。
在信任方面,因为云中所存储的数据和支持的服务对用户而言都是极为关键的,所以需要用户对云供应商给予充分信任,即使其安全措施已经非常完善了。 在法律和政治的限制方面,主要有两点。
在运营效率方面,云供应商需要利用其规模上的优势来降低运营成本,从而降低使用云计算的门槛,同时也能提高其利润。
12.2.2 “电厂”模式就像前言所讲的那样,尼古拉斯·卡尔在《大转变》中非常细致地描述了电力的发展史:刚开始因为直流电传输距离短,所以发电机成为很多需要电力的企业和个人的选择,但是由于能长距离传输的交流电技术的不断成熟,英萨尔的关于电厂的想法成为了现实;之后由于电厂的规模不断增大,电力的价格也随之降低,而且使用起来更方便;最后,电厂模式成为了主流。仔细想来,IT技术的发展和电力技术的发展是何等相似。发电机好比现在的机房,交流电技术好比现在的互联网,而电厂和云计算中心更像是一个模子刻出来的。 总体而言,“电厂”模式是一个公用事业的概念,就是将主要的计算资源都集中到公共的云计算中心,并且遵守类似于电力的220V/110V和通信的7号信令的公开协议,这样企业和个人都能非常方便地使用。因为这种模式在规模上面有极大的优势,其运营成本非常低。而且因为这种模式主要由大型的电信企业运营,它们能得到用户充分的信任。另外,在“电厂”模式中,只存在公有云这一种形式。 虽然“电厂”模式的愿景非常美好,只要接入网络,企业和个人就能随意访问信息服务,同时也卸去了维护计算设备的重担,而且价格低廉,非常安全,并且不会被供应商锁定,但现实是很多方面都只是刚起步而已,特别是在服务的异构性方面,所以要真正实现“电厂”模式,绝对不是一朝一夕的事情。“电厂”模式的用户体验、使用成本和面临的挑战可以概括如下。 1. 用户体验
2. 成本
3. 挑战如果要将“电厂”模式变成现实,将会面对哪些挑战呢? 首先,和“超市”模式一样,“电厂”模式也要在安全和服务质量方面提供令人满意的答案。但因为在“电厂”模式中,云供应商以本国的电信企业为主,所以在信任和政治这两方面上有天然的优势。同时规模庞大使其在运营效率方面提升空间更大,但相应的价格压力也更大。 其次,除了上面这些挑战之外,还包括以下几点。 现有流程的限制。因为云计算将会对企业现有的IT流程产生一定的颠覆,所以如果云计算被大中型公司接受的话,那么它们的IT流程将会受到极大冲击,甚至整个IT部门将会消失。这不仅是一个技术问题,更是一个政治问题。 服务的异构性。由于异构性将使应用和数据很难在云供应商之间进行迁移,被供应商锁定的情况很可能发生,这将会对云计算用户带来极大的风险。而且在云计算的3个层次上,异构性都有所体现。
对遗留应用的支持,比如大型机上的Cobol应用等。因为在很多企业中,遗留应用都属于其核心的应用,如果云缺乏相关支持的话,将阻碍云在这些企业的推广。
12.2.3 “超市”模式和“电厂”模式的区别接下来,总结一下“超市”和“电厂”模式之间的差异,详见表12-2。 表12-2 “超市”模式和“电厂”模式的主要区别
12.2.4 超市还是电厂其实,这两种模型都是非常理想的,没有谁优谁劣的说法。虽然“电厂”模式更吸引人的眼球,而且已经得到了非常多的人的认可,但是“电厂”模式所面对的挑战比“超市”模式多得多。可以预见,短期之内,“超市”模式将会更有用武之地。但从长期而言,因为“电厂”模式潜在的优势更多,特别是在信任、政治和运营效率等方面,所以“电厂”模式将会逐步取代“超市”模式。但是这个过程将会是非常漫长的,需要满足很多条件,包括运营效率的提升、公司IT流程的改造和开放的协议等,所以可以预见,这两个模式将长时间共存。 超市的出现给人们的生活带来了极大的方便,使“开门七件事”不再让人头疼。而电厂的出现更是改变了历史的进程,就像尼古拉斯·卡尔所说的那样:“当每个家庭都拥有便宜的能源接入时,就有了令人难以置信的创造力来利用这些便宜的能源。”对于云计算而言,无论是“超市”模式还是“电厂”模式,都会给人们带来快乐,推动整个社会的发展。 | |||||||||||||||||||||||||||
|
(2个打分, 平均:2.50 / 5) |
雄立科技欢迎您的加盟
作者 XEL-HR | 2011-06-16 07:31 | 类型 工作机会 | 35条用户评论 »
|
| |
|
(1个打分, 平均:5.00 / 5) |

对大宋下一代高端通信系统设计的七个展望
作者 陈怀临 | 2011-06-14 18:21 | 类型 通讯产品 | 117条用户评论 »
|
高端通信系统设计从来就是一个困难的话题。一个优秀的系统设计往往决定了其竞争力和相应的生命周期。 本文试图阐述笔者对下一代高端通信系统设计的一些展望。抛豆腐引砖块,其目的是通过读者的评论,使得美军,共军,国军,伪军等的知识和经验可以共享。使得Open Source的精神发扬光大。 1。 LDF Rule(Legacy Decides Future) 在这个第一重要的法则里,要求的是系统设计师必须了解细节。需要能进能出[想歪了的同学请自己惩罚一下自己邪恶的心灵]。要的是能bottom up。然后在bottom up的基础上,进行top down的设计。缺一不可。只能bottom inside,是一个单纯的工程师;只能top through就是一个玩胶片的大忽悠。 2。 CDMD Convergence Rule 上述的各个Plane都是你中有我,我中有你。[想歪了的同学请自己惩罚一下自己邪恶的心灵]。 在任何一个环节都需要有相应的逻辑部分。整体系统的任何一个平面是通过分布在系统各个环节中的子平面来共同构成的。 这方面最大的挑战是:系统架构师必须对分布式系统的设计非常过敏,sorry,敏感。 在分布式系统设计中,一个最重要的理论悖论是: 在分布式系统中,在任何时刻,在任何一个节点上,是无法知道当时的全局状态的。 这是啥意思呢? 就是,除了上帝,你在一个时刻点T i,是不可能知道Ti时刻系统其他信息的。你能知道的信息只能是T(i+Delta)。这个Delta就是通信开销所带来的。 大白话就是,杨小姐(杨贵妃),从理论上,Y从来就没有吃过新鲜的荔枝,no matter驿道上的马儿跑的有多快。 在这个分布式天生的死穴问题上,带来的问题是最多的。 作为系统架构师,必须对时序逻辑(Temporal Logic)有所掌握。Otherwise, 系统设计一定是漏洞十出。 另外,分布式系统的nature决定了任何全局算法的优化一定不是最优的,而是次优的。 要充分利用计算池的模型,Processing on Demand。 3。CTP(Close To Port, Close To Packet, Close To Payload) Rule 这里的一个设计Case study 是:要充分利用系统中线卡,处理卡,I/O卡上的计算能力。这些计算能力是离端口最近的,对Traffic而言,是Local Bus的距离,而非Interconnect的长途跋涉。 计算是分布的。分布计算的集合就是系统的总体计算和(或)处理能力。 4。 CCNUMA Adoption Rule 只有CCNUMA的应用,才能达到分布式技术的同时,又能支持历史系统,CDMD的融合和Close to Port的法则。 在CCNUMA系统设计中,必须对Memory的分布非常敏感。跨Interconnect,例如QPI,的过分存取,一定是带来硬伤。 系统架构师必须对Cache,L1,L2,和L3和ccNUMA-Interconnect,例如QPI等一些知识有足够的积累和实战能力。否则,很难把握CCNUMA系统。 5。 Hybrid Model Rule 6。 MapReduce Rule 经典的并行计算的MIMD模型应该被广泛的应用。 多个计算流形成一个计算池; MapReduce不应该只是Loosely Coupled Distributed Computing的宠儿,例如Google,Facebook。 MapReduce的思想精髓应该,而且也会被广泛的应用在高端通信系统(Tightly Coupled Distributed Computing)的设计上。 7。 x86+ zero-overhead Linux 任何不adopt Linux/Unix的力量都是错误的。历史的将来会证明这一点。。。 应用决定一切。 Linux的强大中的强大就是无数的应用。 | |
|
(8个打分, 平均:3.75 / 5) |
工具箱
本文链接 |
|
打印此页 | 117条用户评论 »
2011年新世纪优秀人才支持计划开始申报
作者 ss201009 | 2011-06-14 06:56 | 类型 海外学人 | 2条用户评论 »
|
为贯彻落实《国家中长期教育改革和发展规划纲要(2010-2020)》,加快建设一支高素质的高校教师队伍,以高水平科研支撑高质量的高等教育,教 育部将继续实施“新世纪优秀人才支持计划”,择优支持一批具有创新能力和发展潜力的优秀青年学术带头人。2011年度申报工作相关事项如下: 一、申报领域 按以下27个领域归口申报: 1.数学;2.物理;3.化学;4.化工;5.农业;6.林业;7.电子科学技术;8.计算机与通讯;9.生物与基础医学;10.医疗卫生与临 床;11.药学;12.中医药;13.能源;14.资源;15.环境;16.传统材料;17.新材料;18.先进制造;19.管理科学与工程(含工商管 理)。20.哲学、马克思主义、思想政治理论教育;21.经济学;22.法学;23.政治学、社会学、民族学;24.教育学、心理学;25.语言学、文 学、新闻传播;26.历史学;27.艺术学、体育学。 二、申报条件 1.申请者须符合《“新世纪优秀人才支持计划”实施办法》第七条所列各项基本条件。 2.国内申请者应具有中国国籍,且必须通过人事关系所在单位申请,不接受跨单位申报。 3.引进海外青年优秀人才纳入本计划一并申报。 4.坚持公开遴选,择优推荐的原则。加大人文社会科学领域的申报。注重与部门、地方和学校各类高层次人才计划的衔接。 5.已获得“长江学者特聘教授”、“国家杰出青年科学基金”、中科院“百人计划”资助者,不得再申请本计划。 三、申报名额 实行限额申报制度。 四、申报方式 地方所属高等学校以省(自治区、直辖市)教育行政部门为单位,中央部门所属高等学校以主管部门的职能司局为单位,教育部直属高等学校和实施985工程的高等学校以学校为单位,以公函的形式统一申报。不受理其他组织和个人的申报。 五、其它事项 1.申请者须填写《“新世纪优秀人才支持计划”申请书》,一式8份,加盖所在学校和主管部门公章。申请材料(包括附件)必须突出重点,简明扼要,双面打印,不超过40个页码。 2.各单位须填写《“新世纪优秀人才支持计划”申请人清单》1份,加盖所在学校和主管部门公章报送,并以电子邮件的形式提交电子文件(EXCEL兼容格式)。 3.申报截止日期:2011年9月12日(以收到时间为准),逾期、超额和不符合条件的申请材料恕不受理。 4.资助人选确定后,教育部将择优选派部分入选者赴国外高水平大学或研究机构从事合作研究。 5.本通知同时在教育部科技司网站www.dost.moe.edu.cn 上公布。有关附件和电子表格请在网站“下载中心”栏目下载。 联 系 人:李楠 高润生 联系电话:010-66096358 66097382 传 真:010-66096358 66020784 邮 编:100816 邮寄地址:北京西单大木仓胡同35号教育部科技司综合处 电子信箱:zouhui@moe.edu.cn | |
|
(没有打分) |
TCP/IP Sharing – 3
作者 tree | 2011-06-09 21:54 | 类型 专题分析, 科技普及 | 19条用户评论 »
系列目录 新TCP/IP分享
now this is time for tcp/ip sharing – 3 about the network layer. There should be some many errors.
| |
|
(1个打分, 平均:1.00 / 5) |
拨云见日:虚拟化的最后一公里–虚拟化网卡
作者 libing | 2011-06-07 08:00 | 类型 弯曲推荐, 行业动感 | 58条用户评论 »
|
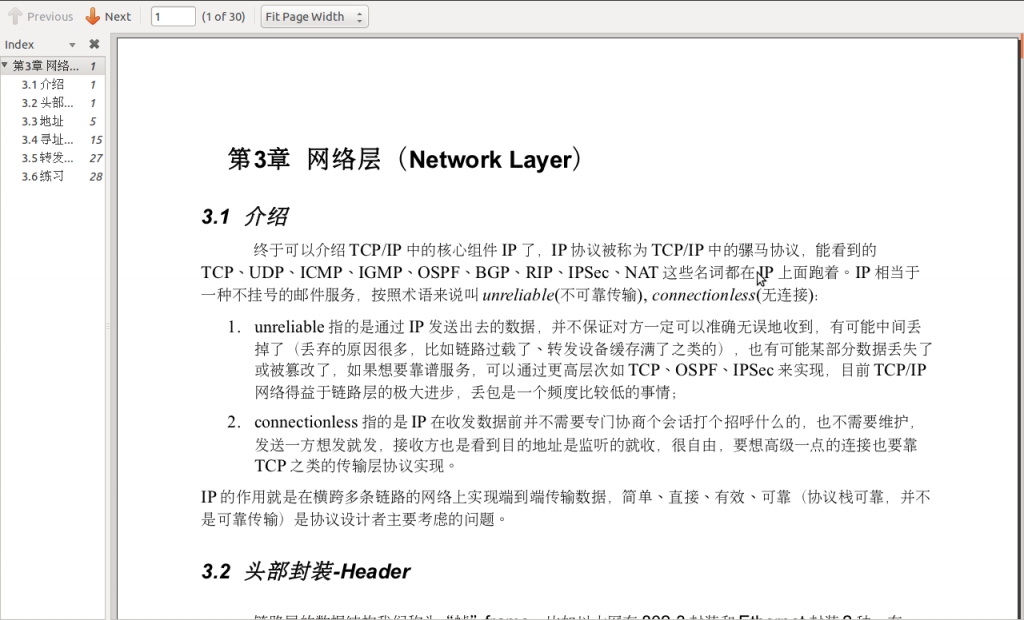
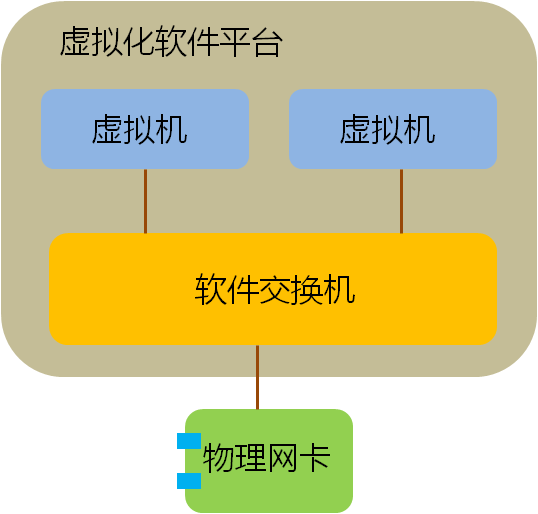
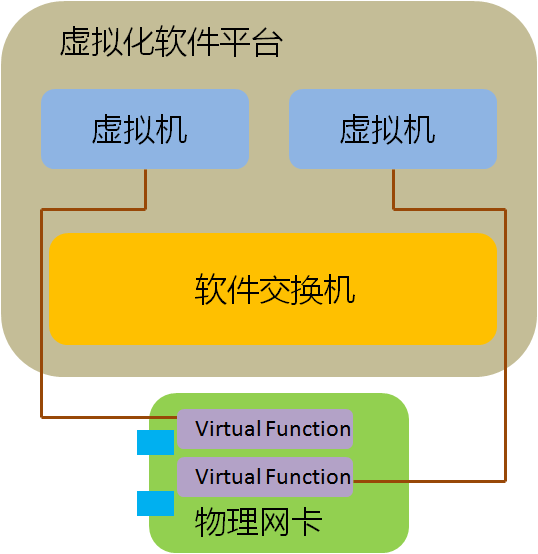
最近看到有国内厂家打出“虚拟化网卡”的概念,我认为这个提法是非常有价值的,可以让更多的人开始思考网络I/O在虚拟化发展中的重要性,但什么才是“虚拟化网卡”?“虚拟化网卡”有何作用?也许这个概念本身并不清晰,在更多的场合仅被作为一个忽悠的工具在使用。另一方面,今天的服务器网卡确确实实在发生一些重要的变化,这些变化将对整个数据中心产业今后的发展产生至关重要的影响。 我希望通过自己的理解,引来更多高手的讨论,最终对这个概念提出一个明确、清晰的认识。毕竟,技术名词是要落地的,我们需要的是“云计算”而不是“晕计算”。 关键词:虚拟化网卡 厂商:Cisco、Intel 。。。 领域:数据中心网络 模糊程度:四星 缘起:虚拟化的最后一公里 在推动虚拟化轰轰烈烈发展的众多因素中,资源的再利用是很重要的一点,当一台服务器只运行一个业务时,其CPU资源往往没有被充分利用,花大价钱购买的CPU就这样沉睡在机架上,干耗电不干活。大多数客户都希望在部署虚拟化之后,将原来服务器可怜的CPU利用率尽可能提高一些。虚拟化软件(如VMWare vsphere、XEN、KVM等)很好地解决了这个问题,在虚拟化软件中,一颗CPU能够被分配给多个虚机同时使用,部署了虚拟化软件的服务器,其CPU利用率往往能够从不到10%增长到70%左右。 这当然非常棒,可任何新技术的发展都是一个以点带面的过程,好像抗生素的发明虽然挽救了成千上万的生命,但人类至今仍在为对抗其带来的副作用而努力。虚拟化技术也不是真空中的产物,它需要同数据中心内部的主机、存储、硬件等方方面面发生关系,当操作系统的运行方式发生变化时,原先的基础架构并不一定能适应这种变化,新的挑战开始浮出水面, 首先告急的就是内存,当CPU主频在Intel和AMD的竞争中,如脱缰野马一般往前发展时,其他部件并没有以相同的速率前进。内存大小就一度制约了单台服务器上虚拟机–也就是VM(Virtual Machine)–数量的增加,由于大量OS实例同时运行在内存中,服务器的内存容量很快捉襟见肘。为了解决这个问题,各个服务器厂家开始疯狂增加DIMM槽容量,现在单台X86服务器最大内存已经可以达到令人匪夷所思的1TB! 内存警报暂时解除后,网络逐渐成为新的瓶颈。当越来越多不同性质的虚拟机跑在一台物理服务器上时,他们的进出数据都会拥挤在一个I/O通道上,这显然是不合理的。以Cisco为首的网络厂家提出了VN-Tag/VEPA等解决方案,来规范虚拟机流量的转发机制,通过在全网部署VN-Tag,不同虚拟机的流量能够被识别,并且在上联交换机上得到很好的QoS保证和安全隔离,但这只解决了一部分问题,虽然VN-TAG能够区分出来自不同虚拟机的流量,但普通服务器网卡只提供一个PCIe通道,在出口网卡上,这些流量仍然混杂在一块。 单一通道造成问题的典型例子是高性能计算环境。 虚拟软件平台也就是Hypervisor往往集成了一个软件交换机,这个软件交换机通过CPU模拟出简单的二层转发功能。传统的解决方案中,多台虚拟机通过一个Hypervisor软件交换机连接到一张物理网卡上,流量进入软件交换机不但消耗CPU资源还产生了时延,这还不要紧,在高性能计算环境中,上层业务对网络I/O的设置有非常敏感的反应,虚拟机往往要求特殊的端口队列模型,如果模型不对,性能可能大幅下降甚至不可用,而单一的物理网卡无法对上层多个操作系统提供不同的队列服务,进一步影响了性能。
既然软件交换机是问题,最直接的思路就是绕过软件交换机。因此,VMWare、Intel、AMD等提出了Hypervisor Bypass方案,也就是说虚拟机绕过软件交换机直接同网卡打交道,这样做的好处是一个虚拟机独享一个PCIe通道,想怎么玩就怎么玩,能够实现接近于访问物理PCIe设备的功能和性能。这个方案在主流平台上有不错的支持,VMWare VMDirectPath和Intel VT-d/AMD IOMMU等相关技术都有比较广泛的部署。
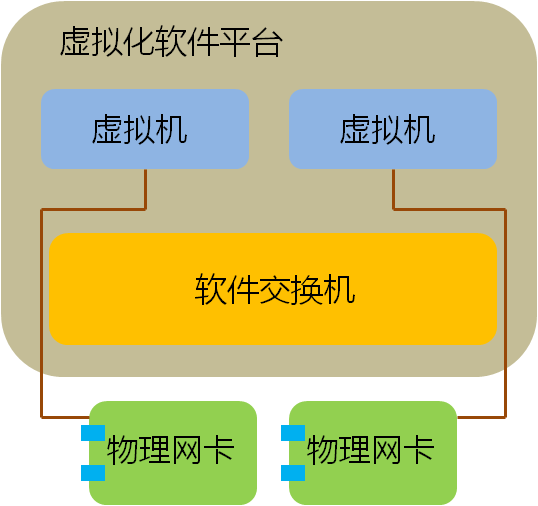
上面这种形式的Hypervisor Bypass满足了虚拟机对I/O性能的要求,但它远非一个一劳永逸的办法,基本是个半拉子工程,其思路是利用物理网卡为VM直接服务,从而暂时回避了传统I/O跟不上虚拟化发展的问题。最大的缺陷就是每个虚拟机都独占一个PCIe插槽,而插槽意味着什么呢?意味着money!在不断扩张的服务器机房内,每一个PCIe插槽都牵动着能耗、散热和空间的支出,更不用说单台服务器上PCIe插槽的数量上限了。这种以大量占用物理网卡数量为代价的方式很快就会遇到PCIe插槽数量的极限,不是一个可持续发展的方案。 也许有人会问,能不能通过优化Hypervisor的网络功能来解决这个难题呢?首先,网络不是虚拟化软件目前的开发重点;其次,软件的开销太大,普通万兆网卡在多VM的传输环境下已经占用了不少系统资源,如果还要精确、高效地模拟不同虚拟机的传输队列,将会消耗大量CPU资源;最后,软件实现的效率也不高。 随着邮件、OA等简单应用在虚拟化平台上的成功运行,越来越多的重要业务将开始向虚拟化迁移,这些业务中很大一部分都对网络I/O有着严格要求。我们搞定了CPU,搞定了存储,搞定了内存,搞定了交换机,却没来及搞定服务器上一块小小的网卡,当其他所有都不再是限制的时候,I/O这块短板开始慢慢显现,成为阻碍虚拟化发展的最后一个瓶颈,也就是接通虚拟化世界的最后一公里。 所以我们看到”虚拟化网卡”应运而生了,这个概念出现在这个时间点是一件自然而然的事,是技术进化到一个阶段的必然产物,只有跨过这个坎,虚拟化才可能开始向更高的段位发展。 那么,下一个问题就是:什么是虚拟化网卡? 什么是虚拟化网卡? 除了基本的数据转发,上层业务对网络的需求可以归纳为以下两点: 1)安全隔离; 2)服务质量保证QoS 实现这两点的前提都是对数据流量进行清晰的区分,只有区分出不同的流量,才能根据业务类型配以不同的保障等级。如果以服务器出口为界,我们可以将数据流过的路径划分为外部和内部两部分。 对于服务器外部网络:VN-TAG/VEPA可以区分出不同虚拟机的流量,并在整个数据中心内部署有针对性的隔离和QoS策略,我们称为“虚拟接入”; 对于服务器内部:虚拟化网卡要在不破坏现有业务机制的前提下,为每个虚拟机提供一个模拟真实的网络通道,这个模拟出来的虚拟通道不仅仅要对VM透明,而且要尽可能重现在非虚拟化环境中的一切网络机制,我们称为“虚拟通道”。只有在这样的环境中,上层业务在向虚拟化迁移的过程中,才不必因为网络环境的变更而做出改动,从而尽量减小迁移成本,加快迁移流程。虚拟机产生的数据通过独立通道进入网卡 ,紧接着被打上标签送往外部网络,反向亦然,对于上层业务来说,感受不到I/O的变化,所有的数据行为同运行在一台独立物理服务器上无异。 因此,我们可以定义虚拟化网卡的核心是“虚拟接入”和“虚拟通道”,只有补上这两块短板,才真正打通了服务器网卡的虚拟化瓶颈,彻底解决了服务器端的网络I/O限制。
在这里有很多针对虚拟接入的非常棒的讨论,下面介绍虚拟通道技术。
SR-IOV 虚拟通道的实现方式有很多,由于其在未来虚拟化环境中的重要性,大佬们纷纷提前卡位,其中PCI-SIG制定的SR-IOV影响力最大,其背后推手是Intel、Broadcom等巨头。 大多人认识虚拟通道都是从SR-IOV开始,SR即Single Root,IOV为I/O Virtualization,合起来就是将单个PCIe设备(Single Root)–如一个以太网卡–对上层软件虚拟化为多个独立的PCIe设备。 SR-IOV虚拟出的通道分为两个类型,PF(Physical Function)和VF(Virtual Funciton)。
每一个VF都好象物理网卡硬件资源的一个切片,对于虚拟化软件平台Hypervisor来说,这个VF同一块普通的PCIe网卡一模一样,安装相应驱动后就能够直接使用。假设一台服务器上安装了一个单端口SR-IOV网卡,这个端口生成了4个VF,则Hypervisor就得到了四个以太网连接。 SR-IOV的实现依赖硬件和软件两部分,首先,SR-IOV需要专门的网卡芯片和BIOS版本,其次上层Hypervisor还需要安装相应的驱动。这是因为,只有通过PF才能够直接管理网卡的I/O资源和生成VF,而Hypervisor要具备区PF和VF的能力,从而正确地对网卡进行配置。 在SR-IOV的基础上,通过进一步利用Intel VT-d或AMD IOMMU(Input/output memory management unit),直接在VM和VF之间做一对一的映射,在这个过程中,Hypervisor的软件交换机被完全Bypass掉了,同传统的VM DirectPath相比,这种方式即实现了VM对VF硬件资源的直接访问,又无需随着VM数量的增加而增加物理网卡的数量。
在业界厂家的大力推广下,SR-IOV已经成为虚拟化数据中心一个非常重要的演进方案,支持SR-IOV的网卡开始大量出现,其中不得不谈谈的就是Cisco名声大噪的Palo卡。 Cisco Palo Cisco这块红得发紫的网卡大名M81KR,昵称Palo。 Palo是一块SR-IOV网卡,但它又不是一块标准的SR-IOV网卡(×_×!),这句话翻译成人类的语言就是,Palo能够兼容SR-IOV的所有行为,但无需Hypervisor对SR-IOV的支持。 之所以Cisco要玩得这么特立独行,是因为PCI-SIG自推出SR-IOV后,其市场推广并不是太给力,前面说过,要实现多个虚拟通道需要在Hypervisor上安装对应的驱动,但目前为止只有XEN和KVM等开源系统比较积极地提供了对SR-IOV的支持,VMWare vsphere和Microsoft Hyper-v这类主流平台迟迟不见动静。 数据中心市场经过一轮大浪淘沙,已经逐渐明确了未来的发展方向,谁越早拿出一个切实可行的解决方案,客户就会跟谁走。Cisco在数据中心市场提前数年布局,投入不可谓不重,目前看来,思科是是唯一在各个方面有充足储备的厂家,其他人的下一代数据中心网络产品线还很模糊。尽管Nexus平台优势明显,但后面的追兵一刻也没松懈,大家都在争分夺秒地划分地盘,HP已经在给802.1qbg拼命造势,如果这个节骨眼上,客户因为SR-IOV的不成熟限制了虚拟化的部署,拖累了整个市场向虚拟化的转型,相当给了其他厂家喘息的机会,这是Cisco最不希望看到的局面。 因此,思科在Palo上又一次采取了以往屡试不爽的策略,一方面提供对公开标准的支持,一方面抢先推出自己的实现版本,以促进市场尽快成熟。同SR-IOV类似,Palo最大能够实现128个以太或存储通道,但Hypervisor无需支持SR-IOV,思科会单独推出Palo在各个平台上的驱动。能做到这点,一方面是因为思科自身迫切的需求,另一方面,其网络大佬的影响力,也推动了软件厂家的合作。 Palo作为市面上第一块真正意义上的虚拟化网卡,同时实现了基于VN-Tag/802.1qbh的虚拟接入和类似SR-IOV的虚拟通道功能,第一次将网络接入延伸到VM层面。在部署了Palo卡的刀片服务器上,VMWare vsphere上VM的流量被直接发送到一个独立的PCIe通道,这些数据在此随即被打上VN-Tag标记,然后送往上联交换机。在这个环境中,上联交换机、服务器网卡、甚至刀片机框IO模块不再是分裂的对象,而是合并为一个逻辑上统一的接入交换机,这个接入交换机能够直接看到VM的端口,对单个VM的数据流量进行安全隔离,对以太和FCoE流量实施QoS策略,而Hypervisor无需再维护一个软件交换机,原来被软件交换机占用的CPU资源能够用来运行更多的虚拟交换机。 虚拟接入和虚拟通道相辅相成,在Cisco Palo上第一次实现了同物理机类似的虚拟机接入。 后面的故事 近年来,数据中心的发展如火如荼,VN-Tag、FCoE等新技术层出不穷,新一代数据中心架构逐渐成形,虚拟化网卡是这个拼图的最后一块。Cisco Palo作为这个领域的第一个尝试,拉开了服务器网卡的升级序幕,网卡厂家将开始新一轮的技术竞争,MR-IOV、Hypervisor Bypass情况下的虚拟机动态漂移等领域将成为下一代技术热点。而随着虚拟化网卡的不断完善,数据中心的转型将开上一条真正的快车道。 五分钟Q&A 1)什么是虚拟化网卡? 虚拟化网卡要能够对不同的虚拟机提供独立接入,区分不同虚拟机的流量,以提供相应的安全和QoS策略。在实现方式上,虚拟网卡要支持”虚拟接入”和“虚拟通道”技术。 2)什么是“虚拟接入”? “虚拟接入”技术利用标签,在全网范围内区分出不同的虚拟机流量。 3)什么是“虚拟通道”? “虚拟通道”在物理网卡上对上层软件系统虚拟出多个物理通道,每个通道具备独立的I/O功能。 4)什么是SR-IOV? SR-IOV是PCI-SIG推出的一项标准,是“虚拟通道”的一个技术实现,用于将一个PCIe设备虚拟成多个PCIe设备,每个虚拟PCIe设备如同物理物理PCIe设备一样向上层软件提供服务。 5)SR-IOV在网络虚拟化方面有和用处? SR-IOV网卡能对上层操作系统虚拟出多个PCIe网卡,每个网卡可以实现独立的I/O功能。独立的通道能够实现更强的安全隔离、更完善的QoS和更高的传输效率。SR-IOV目前支持在一块PCIe网卡上虚拟出256个通道,是实现虚拟化网卡的基础之一。 6)部署SR-IOV需要什么条件? 部署SR-IOV需要支持SR-IOV的硬件网卡,和支持SR-IOV的软件操作系统。 7)SR-IOV同Hypervisor Bypass是一个玩意吗? 不是。 尽管SR-IOV常常同Intel VT-d等Hypervisor bypass技术配合使用,但两者各自独立,SR-IOV的功能是虚拟出多个PCIe设备,Hypervisor Bypass实现的是虚拟机对底层硬件的直接访问。 8)什么是Cisco Palo? Palo是Cisco推出的兼容SR-IOV的虚拟化网卡,能对上层虚拟出128个以太或存储通道,并且支持VN-TAG/802.1qbh虚拟接入技术。 10)SR-IOV是实现虚拟网卡的唯一方式吗? No 市场还有很多公司提供类似的I/O虚拟化解决方案,如Xsigo等。 | |
|
(9个打分, 平均:5.00 / 5) |
GPL版陈首席
作者 coder | 2011-06-06 21:00 | 类型 弯曲推荐, 行业动感 | 14条用户评论 »
|
古之学者必有师。师者,所以传道、受业、解惑也。人非生而知之者,孰能无惑?惑而不从师,其为惑也,终不解矣。生乎吾前,其闻道也固先乎吾,吾从而师之;生乎吾后,其闻道也亦先乎吾,吾从而师之。吾师道也,夫庸知其年之先后生于吾乎?是故无贵无贱,无长无少,道之所存,师之所存也。 嗟乎!师道之不传也久矣!欲人之无惑也难矣!古之圣人,其出人也远矣,犹且从师而问焉;今之众人,其下圣人也亦远矣,而耻学于师。是故圣益圣,愚益愚;圣人之所以为圣,愚人之所以为愚,其皆出于此乎!爱其子,择师而教之,于其身也,则耻师焉,惑矣!彼童子之师,授之书而习其句读(dòu)者,非吾所谓传其道解其惑者也。句读之不知,惑之不解,或师焉,或不(fǒu)焉,小学而大遗,吾未见其明也。巫医、乐师、百工之人,不耻相师;士大夫之族,曰师曰弟子云者,则群聚而笑之。问之,则曰:“彼与彼年相若也,道相似也。位卑则足羞,官盛则近谀。”呜呼!师道之不复可知矣!巫医、乐师、百工之人,君子不齿。今其智乃反不能及,其可怪也欤! 圣人无常师。孔子师郯(tán)子、苌(cháng)弘、师襄、老聃。郯子之徒,其贤不及孔子。孔子曰:“三人行,则必有我师。”是故弟子不必不如师,师不必贤于弟子。闻道有先后,术业有专攻,如是而已。 李氏子蟠(pán),年十七,好古文,六艺经传(zhuàn),皆通习之,不拘于时,学于余。余嘉其能行古道,作《师说》以贻(yí)之。 今天,我的 Mphil (master by research) thesis 终于评审完了。上来 tektalk 写一篇感谢我的老师,陈首席的文章。感慨万千,不知如何下笔。 copy 一份 《师说》顶置。 05 年,我还是一个大一 freshman,一个月黑风高之夜,在学校网吧 (学校不让大一学生上网,傻逼学校),误入 CLF (www.linuxforum.net)。当时就傻眼了,什么 V 总啊,茶总啊,轮总啊,斯基啊。开始把 CLF 翻个地(注意儿化音)掉。 BNN 的帖子总是直指人心。鼓起勇气给偶像发个信求教一下,没想到,居然收到了回信。 “Sorry for the late reply. I think having a good understanding of computer arch, networking, os, compiler and data structure would be a good start. Since you are even a fresh man yet, please focus on your course study including those math, physics and computer basics. Step by step, have patience; Then you will reach your goal eventually. Best regards, 当你啥都不懂的时候,偶像的一句话是会改变人的一生的。首席的几句话改变了我的一生。 * 忘掉细节,牢牢把握基本概念。 *Computer system 远大于一个 kernel, computer architecture 是 computer system 的核心。 *量化一个系统。 虽然不懂这些话是什么意思,但是牢牢的记住了。 受首席当年在CLF介绍 Xen 和 L4的影响,我有机会在大四的时候去 ERTOS/UNSW ( http://ertos.nicta.com.au/) 作和 L4 有关的 毕业设计。 直到08年本科毕业后去清华陈渝老师那里打杂。首席这个时候已经创办了 tektalk, 我记得是在我评论了一个关于QNX的文章后,首席在 google talk 上加了我。当时激动的几乎晕倒。 想象一下,如果你喜欢打控卫,相当于 斯托克顿 过来跟你打个招呼。 后来我来到了堪培拉村,开始在 ANU 读 Mphil (Master by research). 首席时不时的会指点我两下。字字珠玑。我的 master thesis 的工作离不开首席的鼓励。 09 年的 9 月 1 号,我和首席的一段聊天记录 me: BCORE 我准备动态的 用 write_to_memory 替换 一般的 write
因为一般的write需要 write_allocated
BNN: 你要bypass cache?
me: 恩
BNN: 原因为何?
13:46
I mean, what criteria then for your algorithm?
me: write to cache 需要 1)snooping 得到回复(need waite)
1)需要 allocated cache line
13:47
2)modify it
3)如果连续写的空间很大,又要把以前的modified line 写回去
2 double transactions on links
如果 directly write,
13:48
需要 invilidate cache ilne
和 write back to memory
13:49
BNN: 你的case可以在如下数据访问pattern下解释的过去:
Write without Read.
:写完之后,不会立刻做读操作。
me: 恩
BNN: 否则,代价很大。
me: cache locality 非常不好的情况下
和 不以来这些写顺序的情况下
13:50
BNN: yeah
me: X86的memory consistency对这个write combing 可以 reorder
BNN: 所以,你的算法要与编译结合起来了。
me: 恩
detect
BNN: 这样才能做出漂亮的优化!
最早想去作 compiler 的优化,但是一些商用的 compiler 已经实现了这个功能。后来由于发现 managed language applications 初始化 objects 的开销很大,把这个优化做到了 JVM 里,写了一篇 paper 投到 OOPSLA,然后根据这个 paper 写了我的 thesis.
我的 thesis 讨论了一个非常非常简单的东西:初始化内存。 Managed languages 一般要求创建的 objects 必须是初始化好的 (清 0)。 我们发现这个 清0 开销是很大.
目前的优化一般是想要提高 temporal-locality: 把 清0 留到 创建 objects 的时候来作 (hot-path zeroing)。我们反其道而行之,提出了用 non-temporal instruction 来作,这样 在没有量化分析的基础上,我们提出的方案明显是违背直觉的。某 JVM developer 亲口跟我说 我的方法 make no sense. 我觉得这个 thesis 突出了几个点: 1)优化永远是在量化的基础上来作。
2)Multicore 时代,怎么提高 utilization of shared memory subsystems 是关键。
在thesis, 我写到
“I also would like to thank my shifu, Huailin, who has been teaching me the
architecture of computer systems, and sharing his system-design experiences in the
last few years.”
首席不止影响了我一个人,希望这些影响是GPL的:受到影响的同学继续帮助身边其他的人,这也许就是 education 吧。
| |
|
(5个打分, 平均:3.00 / 5) |