




RSA2011会展观记
作者 yeasy | 2011-02-17 20:20 | 类型 弯曲推荐, 新闻稿, 网络安全 | 36条用户评论 »
|
相信IT安全领域的人对于RSA大会都不陌生。自1991年首次举行以来,RSA大会影响越来越大,规模也越来越大,现在已经成为IT安全领域名副其实的最吸引人的大会。近几年RSA会议的举办地点都是在旧金山湾区,吸引了大批来自世界各地的安全提供商、学者、爱好者参加。今年的举办地点是旧金山的Moscone中心,恰逢其20周年,会议长达5天(2.14~2.18)。感兴趣的读者可以从RSA网站上了解到具体的日程信息。 自1995年开始,RSA大会每年都有一个主题,今年的主题是“The Adventure of Alice&Bob”,安全的味道颇为浓厚。包括Cisco、Juniper、Palo Alto Networks等数百家知名企业均参与了会展。尤为值得一提的是,国内的NSFocus(绿盟)、TopSec(天融信)和新兴的HillStone(山石)等公司也分别携产品参展,吸引了不少目光(这才是民族的骄傲,年轻人的榜样)。总体来看,云计算的痕迹到处可见,Facebook跟Twitter很受安全厂商重视。另外,网关类安全产品在提到性能时基本上都是100G以上。 除了在大厅中进行的会展之外,还有几十个专门的技术类讲座。几乎设计所有安全热点问题,包括云、P2P、加密等等。 下面是在展会现场拍到的一些场面。
一直忙忙碌碌的Registration Desk。
Cisco跟Juniper今年看起来十分低调,位置极佳,但不是那么热闹。
Paloalto Networks位置也不错,关于NGFW的讲解十分风趣,吸引了大量的人气。
绿盟准备很充分。
山石团队,干劲十足的小伙子们。
别具一格的中关村联盟。中国人走的很不容易啊。
EMC跟VMware“心有灵犀”地大炒云跟虚拟化。
CVM也吸引了大批眼光。
美女助阵是大多数展台的统一伎俩。
吸引眼光的另一伎俩是抽奖——奖品不约而同的都是IPad。
电视台现场搭了直播棚。 下面是部分其他参展企业的情形。
| |
  (9个打分, 平均:4.89 / 5) (9个打分, 平均:4.89 / 5) |




























华为拒绝剥离3Leaf科技资产。奥巴马最后拍板
作者 陈怀临 | 2011-02-16 18:59 | 类型 行业动感 | 60条用户评论 »
|
【陈怀临注:下面是一个转载的报道;来自Reuters的报道为:Huawei resisting calls to divest 3Leaf。其他相关英文报道可参阅 Government panel may urge Huawei-3Leaf veto。来自高性能计算HPCWire的一些报道摘要如下:An international technology transfer between a Chinese telecommunications-equipment maker and a Silicon Valley-based IT company could have serious implications for national and economic security. Last May, China’s Huawei Technologies Co. purchased the assets of bankrupted 3Leaf Systems for $2 million. 3Leaf’s I/O virtualization solution enables multiple x86-based systems to be transformed into a powerful supercomputer.3Leaf was a player in the HPC space, but despite its innovative technology, the company eventually succombed to the economic downturn. Now a government panel is reviewing the cross-border deal and could recommend that President Obama veto it.】 据华尔街日报报道,华为表示,美国外国投资委员会已做出决定,认为华为应当剥除它在去年5月份收购的小型科技公司3Leaf Systems,否则委员会将建议美国总统下令删除这起收购。 美国总统不需要按照委员会建议行事。报道引述华为美国公司负责政府事务的副总裁普卢默(Bill Plummer)说,华为已经决定在总统那里试试运气。普卢默说,对这次审查高度尊重,公司愿意通过谈判达成一项全面的、可望减轻部分官员担忧的国家安全 协议;退出和剥离将会损害我们的品牌和声誉。 3Leaf是一家位于旧金山湾区的创业企业,所创立的技术允许不同计算机组一起运作,成为 一台更强大的机器。华为起初没有披露这桩200万美元的收购,因为它认为自己只是收购了知识产权之类的部分资产,并聘请了3Leaf公司的15名员工,没 有必要披露。但五角大楼官员知悉这起交易后采取罕见措施,要求华为事后申请外国投资委员会审查。 | |
|
(10个打分, 平均:4.40 / 5) |
《弯曲评论》三周年庆:再论弯网读者世界分布图
作者 杰夫 | 2011-02-15 15:57 | 类型 专题分析, 弯曲推荐 | 40条用户评论 »
系列目录 《弯曲评论》周年纪念专稿
新春大吉,《弯曲评论》也迎来了她的三岁生日,在这里弯网编辑部祝各位过年好,情人节愉快。每到弯网周年之际,我们都会发表一篇文章,分析前一年中读者在世界各地的情况,进而推断中国科技人员在世界的分布。今年也不例外,我们将延续这一光荣传统。在前一年中,弯网的访问量同比翻番还多,读者的分布也从130扩大到146个国家(见附图)。从图上看,欧洲,南、北美洲已经实现全覆盖,没有读者的国家主要集中在中非和中亚的几个斯坦。看来,那些地区是中国技术人员还没有渗透到最后几个死角。 按国家(和地区)排序,前二十位最大的读者群来自:中国(大陆)、美国、加拿大、香港、台湾、英国、日本、新加坡、澳大利亚、德国、法国、瑞典、马来西亚、印度、芬兰、韩国、俄国、荷兰、肯尼亚,和新西兰。这其中,俄国和肯尼亚是新面孔,肯尼亚能进入前二十令人有些意外,莫非中国最近在那里拿下了大项目?
中国大陆的读者分布(见左图)从一年前的310个城市剧增到550个,成长惊人。前三名依然是北京、上海、和深圳,加起来占总人数的一半左右,因为这三个城市集中了中国大多数的技术企业。其中北京的读者群又相当于上海和深圳的总和,凸显出其在中国技术行业一枝独秀的地位(或是权力垄断的结果?)。第四到二十名是广州、南京、杭州、成都、武汉、苏州、西安、福州、长沙、重庆、天津、合肥、泉州、沈阳、无锡、济南、和厦门。其中重庆和沈阳是新进,大连和郑州被挤出前二十。台湾的读者来自20个城市,最多的是三重、土城、桃园、台南,和Nei-Hu(?)。台北竟然退出前五名,情何以堪。 美国的读者分布在所有的五十个州,再加上DC。最多的还是加州,占总数的将近一半。其他人数较多的州依次是纽约、麻州,北卡、和德州。前五名的名单和去年一样,都是美国科技公司最密集的地方。人数最少的五个州是阿拉斯加、蒙大拿、北达科他、南达科他、怀俄明。 加州的读者来自254个城市,人数北加多于南加,主要集中在湾区、洛杉矶,和圣迭戈地区,但从最北的Crescent City到最南的Bonita都有弯网的读者。麻州的读者来自103个城市,主要分布在波士顿周围,人数较多的有Acton,Cambridge,Boston,Hanscom,和Brooklyn Village等。 下面是美国纽约州,麻州和加拿大的读者分布图。
加拿大的读者分布从108狂增到191个城市,最多的是Burnaby,Richmond,温哥华,Outremont,和多伦多。 印度的读者来自37个城市,今年有两个城市的访问量超出了去年的冠军班加罗尔(印度硅谷),它们是Gurgaon和Hyderabad。另外孟买,Pune,Chennai,和新德里的访问量也比较多。俄国读者分布在27个城市,最多的是莫斯科和圣彼得堡。 弯网的读者基本覆盖了欧洲所有国家,英国最多,其次是德国和法国。英国的读者分布在148个城市,人数较多的有伦敦,Bashingstoke,Kings Langley,剑桥,St Albans, Welwyn Garden City, Leicester等。德国的读者分布在134个城市,慕尼黑最多,其次还有柏林,Bad Vilbel, Darmstadt,波恩,斯图加特,和法兰克福等; 法国读者来自113个城市,巴黎最多,其次还有Montrouge, Courbevoie,Issy-les-Moulineaux,VanvesBois-Colombes,里昂等。以下是欧洲三国的读者分布图。
澳洲的读者来自24个城市,最多的是堪培拉,其次是悉尼,墨尔本,布里斯班,和Adelaide。我们的读者还遍布日本和韩国全国各地,日本有210个城市,最多的是东京,Shibuya,名古屋,Shinjuku,和大阪等。 韩国有39个城市,最多的是汉城,仁川,Gwacheon-si,和安阳等。 南美洲和非洲的读者相对较少,但除中非几个国家外,绝大多数国家都有弯网的读者。访问量较大的国家有巴西、加纳,埃及,南非、摩洛哥,和委内瑞拉等。 总体来看,弯网的读者分布较上一年更加广泛,总人数也在迅速增加。弯网的作者群同样也在扩大中,除四位创始人外的作者贡献数量和质量今年都有显著进步。到昨天为止,弯网共发文2857篇,评论25338条,打分5908次。 展望新的一年,让我们大家共同努力,把《弯曲评论》建成在中文科技界,一个严肃、权威、并有重大影响的品牌。 谢谢大家。
弯曲评论周年纪念文章:
附:下图为弯曲评论读者在世界各地的分布。颜色越深表示读者越多,白色为没有读者。
| ||||||
|
(6个打分, 平均:5.00 / 5) |








关于上班的一些事儿
作者 kernelchina | 2011-02-15 14:59 | 类型 行业动感 | 42条用户评论 »
|
零碎的一些感想,就当餐后的一点笑料看吧,切勿产生共鸣^-^ 1) “想要”,“得到”和“做到” 这是士兵突击里面的一段话,“想要”并且“得到”之前,需要“做到”。这就是设定目标,并努力实现的过程。没有人会为一个目标喝彩的,做到或者达到才能得到肯定。过程需要自己负责,结果才是老板想要的。但是,如果完成了目标,却没有相应的回报,这种滋味才是最难受的。不匹配的次数多了,人的积极性,自信心都会受到打击,这时候最好换地方。所以最好是自己设定目标,自己给自己奖励,这样才不至于失望。 在公司里面,没有人会做活雷锋的,无利不起早,也就这么点事儿。 2)”不抛弃“,”不放弃“ 没有毅力和韧性是不会成功的,不能承受打击是不行的。跌倒了,爬起来,继续往前走,这才是正常的心态。任何人都不会是一帆风顺的,所以要学会自嘲,学会放松,及时调整心态,和前进方向。只有偏执狂可以生存,但是心理偏执的人,就是心理有问题。做事需要偏执,做人不能偏执。 3)关于领导 任何时候都需要和领导搞好关系,保持一致。但是要分情况。比如把底下的人压榨,再压榨,却不给一点好处,利益都是自己享用的人;比如只会许空头支票,从来都不兑现的人;比如不能和底下的人搞好关系的人。这种领导要坚决的躲开。如果不是利益共同体,那团队是不会长久的。不会或者不愿或者不能分享的领导不是好领导。健康的团队是可以成长的,不健康的团队都是在苟延残喘。 4)关于政治 有人的地方就有江湖,有人的地方就有政治。有时候需要分清楚,哪些是政治,哪些是形势逼人。政治是个很奇怪的东西,利益和政治是结合在一起的。没有人能独善其身。 5)关于信息对称 职位越高,掌握的信息越多;职位越低,掌握的信息越少。信息不对称,导致”想要“和”得到“的东西不一致;也会导致一些猜疑或者是腹诽。但是信息少有时也不是坏处,圣人治国,需要愚民,知道做什么就行了,不需要知道为什么要做。信息不对称,是保证组织架构稳定的前提,什么都是透明的,那只是理想,是不可能实现的。 6)关于尊重 尊重他人是一个基本准则。但是很多年前人不能做到这一点,牛逼哄哄并没有任何好处,学会谦虚,才能与人相处,才能学习别人的长处。尊重他人说话的权利,即使你不同意。道理是说清楚,辩清楚的,恐吓或者要挟,或者扰乱视线都是没有用的。 7)关于跳槽 跳槽是不可避免的。但是,在一个地方待的时间越长,积累就越多。所以需要跟上大部队,否则就会掉队。不过实在是没办法保持一致了,换个地方也可以。毕竟这只是个工作,还没到要拼命的地步。不过跳槽的时候不要意气用事,因为那对自己一点好处都没有。多看看,多听听,想好了再动,于人于己都方便。即使想要走,也不要抱怨什么,记住这只是工作,不是战场。 8)关于发展 对于自己想做什么,应该有所思考,不管是跟随自己的心,还是跟随钱的脚步,做任何事,都要百分之百投入。如果不是百分之百投入,那说明很大一部分时间是在浪费生命。做什么不要有昧良心的感觉。如果做销售,做公务员,把陪客户唱个歌,吃点,喝点,玩点什么的,都觉得是昧良心,有负罪的感觉,那趁早别干了。每天心里都很纠结,没那个必要。做自己觉得开心,觉得有意义的事情就行了。工作而已,只要不是犯罪,何必自己折磨自己。 9)关于外企 外企是适合女人和小孩(刚毕业)待的地方,但事实上,很多年富力强的中青年挤在外企里面做个界面,做个中文化等等,这样实在是浪费人才。外企适合女人是因为外企还比较遵守中国的法律,不会做出格的事(比如对孕妇的照顾),工作相对轻松稳定;适合于小孩是因为外企的技术力量强,能学很多东西,做的东西相对简单。但是,大部分外企在中国的研发基本上就是辅助性的,基本上就是人家玩剩下的,或者人家不想玩的,真正在中国独立研发产品,开发市场的,很少。就目前来看,外企的工资水平已经没有以前那么诱人了(中青年就是冲着个去的),从发展的角度来看,国内的企业有更大的空间,虽然可能累一点。在外企里面学点技术,就离开是个很好的选择,其他的,对成长没有帮助。 10)关于本文 本文就是在无聊,郁闷,以及低潮的时候,发发感想,娱乐自己的一些无聊文字。成功人士是不屑于写这些东西的,而且成功人士都是上娱乐版,不像码农,来的都是科技版,还是弯曲这样一个码农集散地。不过这也是一个交朋友的文章。如果哪个码农看见了,感觉惺惺相惜,能认识一下也不错,呵呵。 如果餐后感觉心情舒畅多了,那么你就已经看完本文了,谢谢支持。 | |
|
(15个打分, 平均:4.53 / 5) |
弯曲评论荣誉推荐:Intel Westmere-EP评测
作者 陈怀临 | 2011-02-14 21:28 | 类型 芯片技术, 行业动感 | 2条用户评论 »

NGFW评析
作者 kernelchina | 2011-02-14 21:22 | 类型 网络安全, 行业动感 | 81条用户评论 »
|
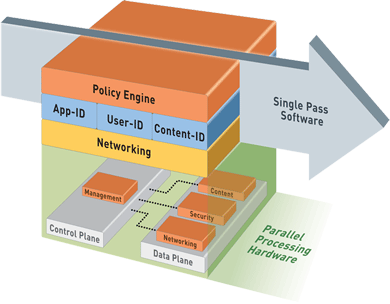
NGFW(Next generation firewall)是近几年出现的一类新产品,它的定义可以参考Gartner report 这类产品的始作俑者是PAN(Palo Alto Networks http://www.paloaltonetworks.com/),我们来看看 这里面有些什么新东西。 先贴张图:
(http://www.paloaltonetworks.com/images/content/sp3.gif) PAN在policy里面引入了三个元素:
这些ID是什么意思哪? APP-ID是DPI/DFI(或者AI(application identification))的结果。怎么理解哪?现在很多应用协议都可以运行在http上,http变成了一个承载协议,如果只控制http,显然是粒度太大,如果能区分出里面的QQ, p2p(emule, bt等),facebook, twitter,控制的粒度更细,对用户就越友好。 点评:这里面有几个问题我还没有搞明白
User-ID需要和企业内部的Auth服务或者UAC/NAC服务结合起来用。用户登录以后,就会有与之绑定的ip地址,policy里面可以匹配相应的用户id。这应该不是什么新东西,很早的防火墙里面就有这个功能了。如果用户登录以后,在防火墙上会下载相应的访问控制策略,这样还有点新意,也就是说,访问控制策略是和用户动态绑定的,并不需要静态加载到防火墙上。但这需要单独的策略服务器,而且如何策略服务器失效,用户是允许访问,还是不允许访问哪?系统里面交互的部件越多,控制越复杂,出错的几率就越高。 点评:协议里面没有User-id,所以需要把User-id映射到ip地址或者mac地址。用户需要通过防火墙认证才能访问资源(防火墙本地认证, 或者远程认证,使用已有的认证体系)。如果能够一次登录(Single sign on),处处可用,就更方便了。但不同的服务有不同的认证, 授权体系,想统一起来,难。 Content-ID顾名思义,应该是访问对象的ID。这个和APP-ID的问题是一样的,那就是粒度。Content-ID应该在DLP(data leakage prevention)里面会用到,或者是URL filtering。什么是content?是URL,还是URL指向的内容,还是更深一层的内容。 点评:细粒度的控制会增加管理的难度,如果没有好的管理工具,会很难用。 从PAN的产品来看,硬件方面基本上没有什么新意(PAN没有chassis-based的产品,也就是说,在高端的竞争力会差一点,不过PAN的目标市场是企业市场,产品应该足够用了)。不过在它的产品图里面有一个content id的卡,不知道是不是一个专用的卡,做这么一个卡的用途是什么哪?提高性能,难道说multi-core的性能不够用,还需要专门的协处理器?还是PAN有卖这个卡的想法? PAN创新的地方在于把app-id, user-id, content-id引入policy,这应该是安全理念的创新。传统的防火墙控制的是5-tuple,粒度太粗了,对IT管理员不怎么友好。总的来说,防火墙就是一个访问控制的设备(NAT是网络功能;VPN保护数据安全,这些是防火墙的基本功能,至于UTM, IDP是另外一个话题,这里就不说了),控制source到destination的访问。如果把source换成User-ID,而把destinaton换成app-id和content-id,是不是更直观一点哪?当然是了。但是,管理简单了,所对应的底层逻辑就会很复杂。因为,不管是user-id,还是app-id,content-id最终还是要映射到packet,要做到上层的策略和底层的实现一致,这个相当难。 PAN还宣传什么single-pass的架构,这个基本上就是在恶心人。比如攻击旧防火墙的firewall policy/av policy/vpn policy等等,有多套,需要match多次,而PAN只需要match一次。能发现这个问题应该还是了不起的,但是新公司,新产品,总得有一点不一样的东西,传统的防火墙已经是补丁摞补丁了,要做新衣服,就比较困难;而PAN算是做件新衣服,如果还是补丁摞补丁,那才叫寒碜。 安全和易用是对立的。因为安全基本上就是在给用户上枷锁。如何让用户在可忍受范围内,实现整个业务流程的安全,是每个从事安全行业的人需要考虑的问题。比如采用三种不同的密码保护用户帐号是很安全的,但是如果登录时需要用户用三种不同的方式认证,估计会把用户搞疯掉。多重方式保护用户帐号,需要区分出主次;需要区分出用户的不同操作;需要区分出帐号的重要程度。(这个话题可以展开说,应该还有很多可以挖掘的东西)。 从这个角度来说,NGFW提升了防火墙的易用性,使防火墙与用户的业务结合更紧密。至于在实际环境中的效果如何,还需要看它能从传统防火墙哪里抢多大的蛋糕过来。 1: http://www.paloaltonetworks.com/products/ 3: http://www.paloaltonetworks.com/literature/whitepapers/Reducing-Costs-with-NextGen-Firewalls.pdf 4: http://en.wikipedia.org/wiki/Firewall_(computing) 5: http://en.wikipedia.org/wiki/Single_sign-on 6: http://en.wikipedia.org/wiki/Data_loss_prevention_software | |
|
(3个打分, 平均:4.67 / 5) |
华为发布业界首款Terabit处理能力防火墙
作者 netsitter | 2011-02-14 03:24 | 类型 行业动感 | 34条用户评论 »
|
华为很牛啊,这个是硬件、系统架构设计的一个综合实力的体现。 华为近日在2011年MPLS及以太网世界大会上宣布,发布业界首款Terabit处理能力的防火墙Eudemon 8000E(“E8000E”)。该防火墙面向云计算复杂应用环境,采用多级多核的分布式架构,转发、业务加速、QoS、安全计算相分离的组件设计,支持100G接口线速转发,无论是处理性能、接口能力,都是当前业界最高性能。同时,该防火墙支持IPv4到IPv6平滑演进,为大型网络和云IDC(互联网数据中心)的建设提供专业的安全防护。 E8000E承袭华为Single战略,采用华为自研Solar芯片族,交换能力达到每槽位400G,整框的交换能力可达6.4T。业务系统采用带硬件加速的多核CPU,为高效地融合专业安全能力提供了保障。同时,其业务平台也具备灵活业务扩展能力,可提供防火墙、IPS(入侵防御系统)、VPN(虚拟专用网络)等主要安全应用,将来可平滑扩展以支持更多专业安全能力,为客户提供ALL IN ONE的解决方案。 “面对日益增长的社会、企业、个人网络安全危机,华为提供从桌面到系统到应用,从设备到网络到运营的多种方案以构筑端到端的安全防护体系,能更好地帮助运营商、企业保护核心业务,提升运营效率和安全性,承担社会责任”,华为运营商安全产品线总裁雷奕康表示,“安全作为华为重要战略,正在不断的创新以成就客户,华为安全将致力于丰富和完善未来网络应用的安全性”。 首先,单槽400G,得出总共6.4T的交换能力这个问题有点可笑,但也说的过去,纯交换来讲没太多好说的,也没太多意义。但同时引申出来一个问题:槽与主板之间的总线是什么样的,首先是什么总线结构,要是FSB那种,肯定没啥意义,我估计华为也不会那么做,但我觉得这块很重要,因为一旦跑了业务,都得跑业务板卡,所以板卡间的通信就会影响业务处理能力。 框架的主处理器是哪家的?用它来做主业务处理器,及业务流的分发,主处理器的处理能力也是很重要的,当然也包含一个它和内存间的带宽的问题,这块要是做不上去,意义也不大,业内有哪些家能做到TB级?不考虑自己的处理能力,单说分发的话。不知道华为用的哪家的。或者框架的本身就是多路的? 我个人觉得框架这种架构的防火墙核心问题就在板卡互联架构(含框架),和业务流的分发上。 | |
 (1个打分, 平均:1.00 / 5) (1个打分, 平均:1.00 / 5) |
WLRU专利的非专业解析
作者 kevint | 2011-02-12 21:45 | 类型 弯曲推荐, 芯片技术, 行业动感 | 68条用户评论 »
WLRU专利非专业解析
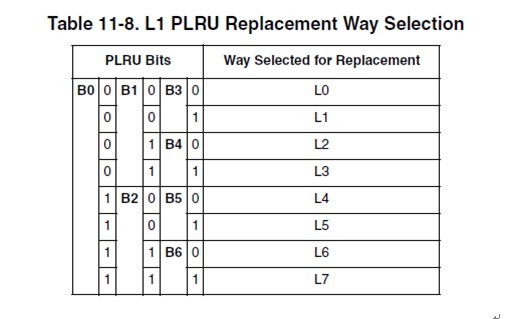
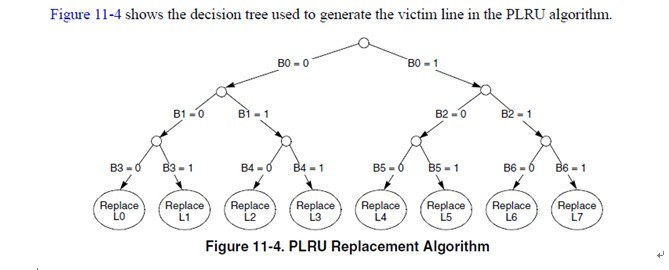
11.6.2.1 PLRU Replacement Block replacement is performed using a binary decision tree, PLRU algorithm. There is an identifying bit for each cache way, L[0–7]. There are seven PLRU bits, B[0–6] for each set in the cache to determine the line to be cast out (replacement victim). The PLRU bits are updated when a new line is allocated or replaced and when there is a hit in the set. This algorithm prioritizes the replacement of invalid entries over valid ones (starting with way 0). Otherwise, if all ways are valid, one is selected for replacement according to the PLRU bit encodings shown in Table 11-8.
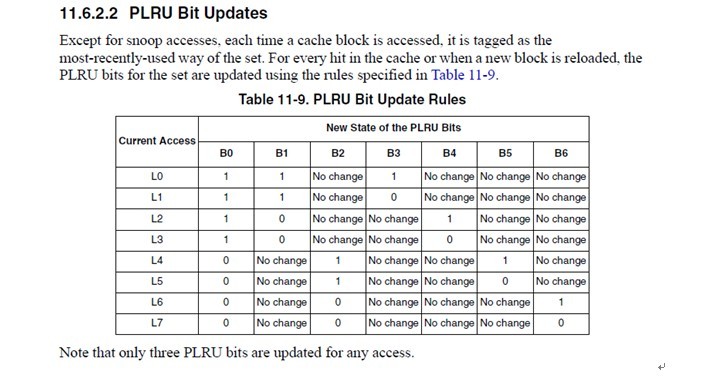
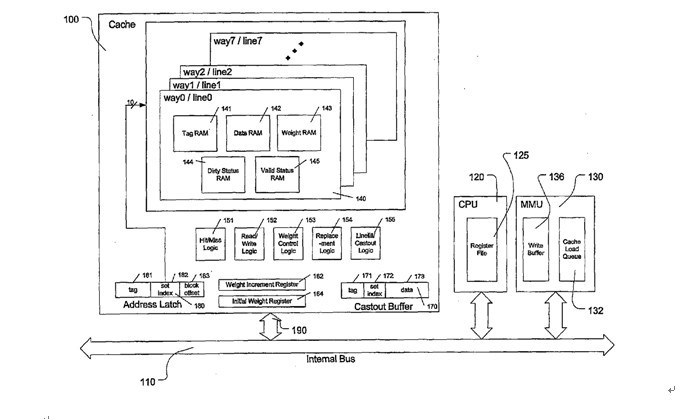
注意,红色的字体是与王大师的WLRU关键的不同点。在e500的cache中,选择victim是在set select中。每一个set,有7个bit用来做cacheline的weight。
这个真值表简单明了,我就不多解释了。 所以当某个line hit的时候,或者当某个line refill到达的时候(其实line refill到达的时候也相当于hit after miss),cache logic根据这个表,更新cache set的这几个bit。 cachemiss的时候,再根据b[0:6]找出一个line换出去就完事了。 一般CPU的PLRU就是这么做了。当然,也可以像某些MIPS那样,random选一个完事。 7.王大师的WLRU是怎么做的
这是王大师专利中的系统框图。 注意一点,就是一个set中,每个cacheline都有一个weight ram。这点与e500不同。e500的victim select是在set select选中后,根据PLRU[0:6]选中一个line。如果WLRU 的weight ram存在每一个line中,那么每一个line都要参与weight的比较,才能算出最终的victim line。这样无疑会增加cache lookup的延迟。 王大师是这么描述的
WLRU的配置 WLRU用“i-r-b”作为weight的算法的参数 i,increment,cache hit后weight的步进。 r,upper limit,weight的上限 b,初始weight。 如i64r128b2。cache hit一次,weight增长64,最大增长到128. cacheline初始weight 为2. 每当cachemiss一次,weight减一。
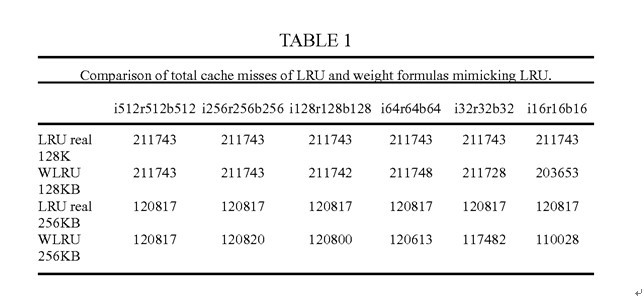
这是王大师在专利中给出的数据。与真LRU比较,证明自己的算法在r比较大的时候,是可以接近真LRU的效果。 这里王大师又搅了一次混水。证明自己的算法在某种情况下可以达到美好的理论值,但是没有详细做横向比较,比如其他LRU算法,跑同样的测试,能达到什么效果。
也没说跑的什么测试例,最后扔下这么一句话,横向比较算做完了。 更尴尬的一点,抛开这个“more than 30% fewer”句型,cache miss rate低30%以上,让人如何理解。比如原先PLRU的miss rate是1%。你低30%。那你就是0.7%。假如PLRU hitrate是99%,WLRU的hitrate就是99.3%。群众关心的综合的performance boost是多少。没说。 回到现实,看看王大师的weight ram实现的成本如何。拿专利中r256为例吧 如果upper limit 是256,那么每个line 要8个bit做weight ram。按照1valid+1dirty+19tag+256data=277bit。增加8个bit,大概增加8/277=2.8%的面积。这个数据,可能就是王大师所说的“WLRU相比于Pseudo-LRU(目前广泛使用的LRU的低代价实现变种)只多2%的晶体管,电路成本的增加微不足道。”的来源。 虽然费料不多,但是这里费时才是关键的。 每一个set要多一个8in 8bit的比较器做weight比较。这个就比较要命了。 另外,当某一个line hit的时候,需要increase它的weight。需要读出weight increment register,再从ram读出当前weight,加起来,比较是否超过了upper limit,如果没超过,再写回weight ram去。cache miss的时候,还要decrease所有line的weight。8条cacheline啊,这些都是要r-m-w的。这cache access的latency。我敲这些字都觉得罗嗦。 所以,这个WLRU做L1 CACHE是没戏了。这点也跟王大师的宣传类似,从哪搞个core,外面挂个WLRU的L2,大力丸子场就算搭起来了。 总之,理论基础铺垫完了。结论也只说能降低“miss rate”. 至于performance boost rate,没提。 8.回到现实—CWLRU 王大师也应该知道,r256,r128的模型只能在论文里做,现实是做不出来的。拿什么救场了。CompactWLRU横空出世啦。 CWLRU使用2bit做weight,并且在每一个cache set增加了一个reference counter。当line hit的时候,weight加1。miss的时候,先decrease reference counter,当reference counter到达某一个threshold的时候,再decrease 所有cacheline 的weight。 weight ram正常情况只有+1和-1的操作,所以可以用counter ram做。不用再读那个weight increment register了。 decrease 1的操作也用reference counter做了聚合。 所以,这个CWLRU,是对上面那一系列繁琐的操作做了一个简化。reference counter越大,weight采样的偏差就越大。 正常人应该看出来,这个CWLRU是非常狗屎的一个近似。。
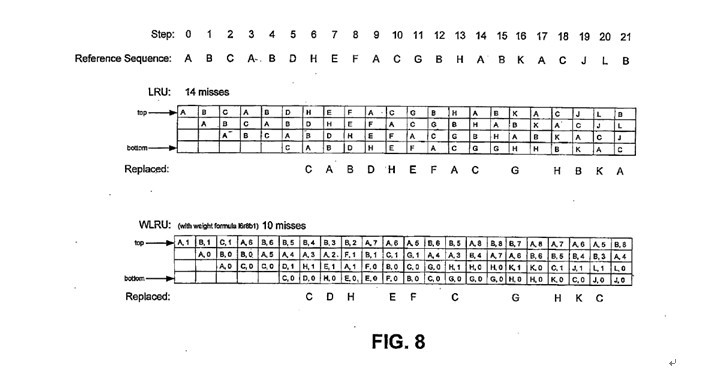
无奈王大师再次扔了一个丸子出来。。。一句话,把这个狗屎的近似算法扶正了。仍旧没有数据支持。 不管是WLRU还是CWLRU,最最要命的一点,就是有几个软件配置的寄存器。这样一来cache对系统不在透明,至少kernel developer在cpu init的时候需要配这个玩意。配多少?难道真的要application aware? 9.专利是需要证明有实际价值才能通过的。WLRU如何证明自己专利是有价值的呢? 一切答案尽在FIGURE8.
我对王大师在弯曲的第一次回复就说过,如果知道cache的组织结构,随便写个程序,让cache hitrate提高/降低10倍,都不是什么难事。 注意step0到step9. 真LRU的情况下,在step3-step7这5个step中,A没有被reference,所以被置换出去了。 而在WLRU中,因为 恰好step0中A被reference了,在step7时所以A的weight更高,没有被置换出去。 王大师在这里客串了一把刘谦,通过自己精心准备的道具(reference sequence)。证明了在WLRU在4way cache上面,miss rate是真LRU的70%。 这里算手下留情了。构造个狠一点的序列,估计真LRU还要惨。 说到这里,各位看官应该大致明白是怎么回事了吧。 王大师说这几年一直在忙着准备测试数据,估计也还是在享受通过构造各种序列降低cache missrate的快感中把。 10.捅破那层窗户纸—WLRU的本质 写这篇文章的时候,我也在思考。WLRU的价值在哪里。个人观点: 其实,这东西就是想是让那些 使用次数少的数据尽量少占用cache。这也是众多PLRU算法的初衷。标准PLRU算法在开销和预测方面选择了折中。而WLRU加入weight ram就让cache有了更大的记忆,weight ram越大,记忆的时间越长,理论预测的就越准确。当然开销也越大。 所以,这个WLRU并没有什么神秘,如首席所说,Jonh Hannessy还没老年痴呆。 前面说了,就算最简单的CWLRU,仍旧过于复杂。不可能做L1 CACHE。 CWLRU能否应用在L2 CACHE上?我想理论上不是没有可能的。不过我不是做IC的,不知道如何实现。另外,专利中的系统框图与ppc,intel的系统框图比起来基本就是小学生的家庭作业。从他的图看,cache是直接physical index, physical tag的。一般也是L2 cache才这么干。 同时,这个东西编译器应该也可以做一些工作,虽然肯定没有运行时预测的准确。但是,应该也是可以做一些工作的。什么时候编译器能够加上cacheline_size, way_number等参数?是不是也是首席说的cache aware application的一种实现呢。 不管怎么样,cache只是整个CPU系统中的一个子系统,CPU又是整个计算系统中的一个子系统,cache的优化,对于系统的加速比是多少?是否有王大师大力丸子场中描述的那般神奇可以“干掉intel”呢? 11.结语 我与公司一个做cache controller的engineer聊了一下,大致对话如下 我:对cache replacement algorithm有没有研究。 他:一般都用PLRU啊。 我:网上有个人说发明了一种cache replacement algorithm,号称miss rate降低了30%-50。能灭掉intel。 他:你给我一个100%hit的cache我也灭不掉intel。哈哈(此人以前做某主流高性能CPU) 我:他就是这么说的。现在正招商引资呢 他:回国忽悠吧。这边估计是没戏了 我:恩,已经回去了。 | |
|
(14个打分, 平均:4.00 / 5) |



手机,智能手机,老东家,弱弱联合,新产品概念机
作者 高飞 | 2011-02-12 16:05 | 类型 专题分析, 移动和设备, 行业动感 | 27条用户评论 »
系列目录 手机,智能手机
首席已经贴了视频,咱的文章已经写了一半了,还是完成算了,把各种新闻和评论都整出来看看,另外,再来点别的料——诺基亚的Windows Phone新概念机! 2011年2月11日,微软和诺基亚在伦敦宣布战略合作。由此看来,诺基亚CEO Stephen Elop去年9月离开微软加入诺基亚属于“快乐的”、“有战略意义的”布局,否则双方不可能如此快达成协议,而且微软CEO Steve Ballmer也承认“双方工程师已经在一起(为新的phone)工作一段时间了”。诺基亚看上Elop同学让他担任CEO,一方面是其软件背景,另一方面据传也是因为Elop是加拿大人,不是美国人(芬兰公司选一个非欧洲的CEO已经够让他们觉得不爽了,让美国人干估计属于不能容忍,请参考《诺基亚换帅,微软Office部门老大换工作》)。 两家公司几乎同时在各自的网站上发布了消息。这是微软的: http://www.microsoft.com/presspass/press/2011/feb11/02-11partnership.mspx 这是诺基亚的: 干货如下:
诺基亚同时大规模reorg(Stephen Elop擅长这个,而且擅长早动手,动大的)。EVP of MeeGo Computers, Mobile Solutions,Alberto Torres,于2月10日离职。同时,4月1日起,诺基亚手机业务方面,设计立智能设备部门(Smart Devices)和移动电话部门(Mobile Phones),分管智能手机和非智能手机,并且都将自负盈亏。智能终端部门由Jo Harlow 领导,除了与微软联合开发Windows Phone以外还将整合之前Symbian、MeeGo和战略业务运营。移动电话部门依然由此前负责非智能手机业务的Mary McDowell 掌管。其它几位传言离职的重要人物都没变化,Marko Ahtisaari负责设计,CTO还是Rich Green,NAVTEQ 依然由Larry Kaplan领导。 至于Symbian,目前的说法是成为授权平台(franchise platform),继续发掘其价值,不会立刻放弃,预计未来还将在growth market卖出1.5亿台Symbian 手机。而MeeGo 将会作为开源移动操作系统项目,偏向于对下一代设备、平台与用户体验的长期探索。诺基亚今年仍将推出 MeeGo 相关的产品。 用一句话说,就是诺基亚选择了壮士断腕,不做软件,专注硬件。操作系统上完全依赖微软,硬件上还面临HTC、三星等选手的挑战;这个选择对于公司毛利率、自身存活能力等都是一个根本的挑战;对微软而言,风险小多了,合作失败不会伤筋动骨。股市对合作的风险评估也如此,周五诺基亚股票大跌13%,微软小跌1%。 这两家的携手其实是必然。诺基亚放弃Symbian能选谁?苹果是封闭系统,而且诺基亚特别抵触苹果,至今还有人在内部将其称作是“那家加州水果公司”。选择Android?这是可能的,而且肯定是Google特别希望看到的。但是摩托罗拉等早就全面倒向Android,诺基亚再加入,最后也就是个二流中的老大水平。骄傲的Stephen Elop性格中有赌性,他宁可选择风险大但是能做一流中的老大的路子。而且好歹,目前和微软还是姻亲,和Steve Ballmer在一口锅里吃过饭,合作的信任度大。 笔者不太相信诺基亚会借微软与Android和Google再眉来眼去讨价还价,原因之一是双方已经投入了很大精力。看看下面的Nokia Windows Phone概念机。
这些流传出来的图片反映了诺基亚一贯的明快设计风格。外形上有点N8和C7的影子。手机下方的“三键套”展示了明显的Windows Phone 7血统。Steve Ballmer说的“双方工程师已经在一起(为新的phone)工作一段时间了”肯定不是虚词。 顺带说一句,Windows Phone 7获得了很多reviewer的赞扬,不过叫好不叫座,消费者没有捧场,因为微软在移动领域过去太让人失望。但是好东西还是好东西,会发光的。Kinect就是个例子。这一把的Microkia或者是Nokisoft手机还真值得关注,看看未来几个季度的智能手机市场占有率会不会洗牌? | |
|
(4个打分, 平均:4.00 / 5) |


{kind=link}
{kind=link}
工程、研究以及学历
作者 appleleaf | 2011-02-12 10:52 | 类型 行业动感 | 38条用户评论 »
|
有一次吃法,道听途说。两个老大在赞扬一个工程师,称其踏实,知道自己学历不高因此立志专心于工程。对这些话我也有自己的感受。总体来讲,我还是觉得这个工程师确实有自知之明。我想不少工程师和我一样,都有研究情节,买了算法、数学模型等等图书装饰书房,仿佛不知道高深的东西自己水平就不够。最终的结果是图书尘封多年,从来没有看过用过。(从这点看,亚马逊的kindle还是很环保的)。自己刚工作的时候也凡事希望涉及到底层的东西,因此也吃了不少亏。 但学历低不能做research这一论断并不完全正确。有些领域确实需要很深的学术背景,例如微软研究院的工作,主要是发paper,估计仅仅接受的通识教育的本科生无法胜任。模式识别,人工智能等领域也应如是。 但是在network上不同,不会微积分、快速排序也可作研究。最著名的RFC作为工程界的产品,都是被广泛认可的权威研究结果。有一篇RFC和有几篇高质量网络论文的权重相比,前者一点也不低。而RFC是工程经验的凝聚而非学术研究结果。另一个很好的例子是华为的路由器等很多工程产品就获得了国家科技进步一二等奖等等最高的研究奖项。 而在网络安全领域更是如此,据说很多小黑客没有接受过通常意义上好大学的教育,在网络安全界确混的很好,他们漏洞也是安全公司主要的研究成果。我想是都是因为自身兴趣加勤奋以及这个领域强烈依赖于系统工程实现的原因。反而是学术界的很少听说有人站出来揭发漏洞,应该并非是学者不屑干这种事情,一个漏洞几千刀,要是笔者能干,一定辞职回家天天发镖去。因此也有说法,hack界藐视学术界的安全研究。 其实无论在哪里,追根溯源,是否可以在公司活好取决于是否关注business问题,而非学术水平甚至技术水平。一个著名的例子是,唐骏同志研发水平在微软垫底,但是较早的关注windows产品的多平台开发,赚取了第一桶credit。而我身边的例子是,公司内最能fix bug的被“挖到”美国总部。关注自身‘技能培训’者则默默无闻。 总之英雄莫问出身工程经验丰富和学术水平高都可以活的很好,都可以做研究。重要的是以业务和结果为导向,闭门造车的研究算法,软件模式等等都相对有限的生命和机会的浪费。 | |
|
(7个打分, 平均:5.00 / 5) |