




移动互联网 。中国
作者 陈怀临 | 2010-04-28 00:39 | 类型 行业动感 | Comments Off
2010年度 中国WEB应用防火墙厂家和产品大全
作者 张百川(网路游侠) | 2010-04-28 00:31 | 类型 网络安全, 行业动感 | 7条用户评论 »
|
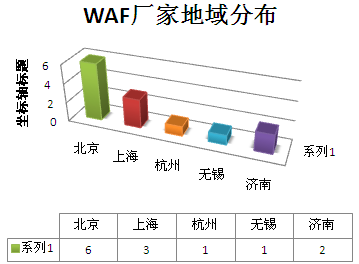
中国WEB应用防火墙厂商与产品大全 北京瑞达时代科技有限公司 北京智恒联盟科技有限公司 北京中软华泰信息技术有限责任公司 广州Safe3 Network Center 杭州安恒信息技术有限公司 济南中创商用中间件股份有限公司 南京铱迅信息技术有限公司 上海天存信息技术有限公司 上海天泰网络技术有限公司 无锡宝界科技有限公司 博威特网络技术(上海)有限公司 PDF版本更完整,更新更及时! | |
 (1个打分, 平均:5.00 / 5) (1个打分, 平均:5.00 / 5) |
网络世博会 。现实世博会
作者 陈怀临 | 2010-04-28 00:29 | 类型 行业动感 | Comments Off
剖析系统虚拟化(4)- VMware ESX 架构
作者 吴朱华 | 2010-04-27 13:54 | 类型 云计算, 行业动感 | 26条用户评论 »
系列目录 漫谈虚拟化技术
上篇文章已经向大家介绍了VMware vSphere,而本篇将继续把重点放在vSphere身上,并向介绍大家vSphere之核心ESX的架构,虽然关于ESX架构的公开资料较少,但是基于这些已公开的资料,并加上我的一些实际经验,我觉得还是能对ESX的架构有一个大致的描述,下图为ESX的架构:
图1. ESX的架构图(点击可看大图)(参【2】) ESX主要可被分为两部分:其一是用于提供管理服务的Service Console,其二是ESX的核心,也是主要提供虚拟化能力的VMKernel。 Service Console简单的来说,Service Console就是一个简化版Redhat Enterprise OS。虽然其不能实现任何虚拟化功能,但是对这个ESX架构而言,它却是一个不可分割的一部分。主要有五个方面功能:
注:虽然Service Console提供了许多功能,但因为其本身资源所限的原因(关于这点,我曾经和一位VMware工程师有过聊天,好像整个Service Console大概只能占有280MB内存和少量的I/O),所以不适合在Service Console中执行一些重量级的任务,比如:上传或者复制虚拟磁盘(Virtual Disk)。 VMKernelVMKernel是由VMware开发的基于POSIX协议的操作系统,它提供了很多在其它操作系统中也能找到的功能,比如,创建和管理进程,信号(Signal),文件系统和多线程等。但它是为运行多个虚拟机而“度身定做”的。它的核心功能是资源进行虚拟化。下面将通过CPU,内存和I/O这三个方面,来讲解VMKernel是如何实现虚拟化的。 CPU 在CPU方面,ESX使用了在第二篇提到的两个全虚拟化技术:优先级压缩(Ring Compression)和二进制代码翻译(Binary Translation)。 优先级压缩,指的是为了让VMKernel获得所有物理资源的控制权,比如CPU。这就需要让VMKernel运行在Ring 0,在其上面的虚拟机内核代码是运行在Ring 1,而虚拟机的用户代码只能运行在Ring 3上。这种做法不仅能让VMKernel安全地控制所有的物理资源,而且能让VMKernel截获部分在虚拟机上执行的特权指令,并对其进行虚拟化。 二进制代码翻译,虽然上面的优先级压缩这个技术已经处理了很多特权指令引发的异常情况,但是由于X86架构在初始设计方面并没有考虑到虚拟化这个需求,所以有很多X86特权指令成了优先级压缩的漏网之鱼,虽然通过传统的Trap-Emulation技术也能处理这些指令,但是由于其不仅需要花时间观测有潜在影响的指令,而且还要监视那些非常普通的指令,导致Trap-Emulation的效率非常低,所以VMware引进了二进制代码翻译这个技术,这个技术能让那些非常普通的指令直接执行,不干涉,并提供接近物理机的速度,但会扫描并修改那些有嫌疑的代码,使其无法对虚拟机造成错误的影响。由于大多数代码都不属于有嫌疑的,所以二进制代码翻译的效率远胜Trap-Emulation。还有经过VMware长达十年的调优,使得二进制代码翻译这个技术越发优秀。 接下来,谈一下的VMware的二进制代码翻译技术的特点:
对于CPU虚拟化而言,只有上面这两种技术是远远不够的,还需要调度技术,也就是需要CPU调度器(Scheduler)。但是CPU的调度器和常见操作系统的调度器是很不同的,因为CPU的调度器的责任是将执行上下文分配给一个处理器,而普通操作系统的调度器则是执行上下文分配给一个进程。同样的是,CPU调度器并没有采用传统的优先级机制,而是采用平衡共享的机制,来将处理器资源更好地分配给虚拟机,同时也能设定每个虚拟机的份额,预留和极限等设定值。在VMware最常用的CPU调度器算法,是“Co-Scheduling”算法,其也常被称为“gang-scheduling”算法,它的核心概念是让相关的多个进程尽可能在多个处理器上同时执行,因为当多个相关进程同时执行时,它们互相之间会进行同步,假设他们不再一起执行的话,将会增加很多由同步导致的延迟。在vSphere中,VMware推出了Co-Scheduling的更新版本,叫做Relaxed Co-Scheduling,它能更好地与虚拟机进行协作。同时,为了更好利用最新推出了多核系统,VMware也给调度器添加很多新的特性,主要集中在两方面:其一是对现有多核环境的探知,比如对NUMA(Non-Uniform Memory Access),Hyperthreading,VM-Affinity的支持。其二是在多核之间进行有效的负载均衡。
内存VMKernel在内存虚拟化方面所采用的核心机制就是“影子页表 (Shadow Page Table)”。在探讨影子页表的机制之前,先看一下传统页表的运行机制,其实也很简单,就是页表将VPN(Virtual Page Number 虚拟内存页号)翻译成MPN(Machinel Page Number,机器内存页号),之后将这个MPN发给上层,让其调用。但是这种做法在虚拟的环境是不适用的,因为当虚拟机从页表得到的翻译之后的页号不是MPN是PPN(物理内存页号),之后需要从PPN再转换成MPN,由于这样将经历两层转换,所以肯定会较高的成本,所以VMware引入影子页表这个机制,它维护为每个Guest都维护一个“影子页表”,在这个表中能直接维护VPN和MPN之间映射关系,并加载在TLB中。所以通过“影子页表”这个机制能够让Guest在大多数情况下能通过TLB直接访问内存,保证了效率。
图2. 内存虚拟化(点击可看大图) 由于虚拟机对内存的消耗胜于对CPU的消耗,同时介于内存的内容同质化和浪费这两个现象在虚拟环境非常普遍,所以VMware在影子页表的基础上引入了三个非常不错的技术来减少内存的消耗,以支撑更多的虚拟机:其一是Memory Overcommit机制,这个机制通过让虚拟机占用的内存总量超越物理机的实际容量来使一台物理机能支持更多的虚拟机。其二是用于减少虚拟机之间相似内存页的Page Sharing,它主要实现是通过对多个虚拟机的内存页面进行Hash,来获知那些内存页面是重复的,接着将多个重复的内存页面整合为一个replica,之后通过CoW(Copy On Write)的机制来应对对内存页面的修改。其三是能在各个虚拟机之间动态调整内存的Balloon Driver,其实现机制就是通过给每个虚拟机安装VMware Tools(可以把VMware Tools看作VMware的驱动)来装入Balloon Agent,在运行的时候,Balloon Agent会和主机的Balloon Driver进行沟通,来调整每台虚拟机的内存空间,来将那些在某些虚拟机上不处于工作状态的内存通过swapping等方式来闲置出来,以拨给那些急需内存的虚拟机。
I/OVMKernel的做法是通过模拟I/O设备(磁盘和网卡等)来实现虚拟化。而且主要选取最大众化的硬件来模拟,比如440BX的主板,LSI Logic的SCSI卡和AMD Lance的网卡,从而提高这些模拟I/O设备的兼容性。 对Guest OS而言,它所能看到就是一组统一的I/O设备,同时Guest OS每次I/O操作都会陷入到VMM,让VMM来执行。这种方式,对Guest而言,是一种非常透明的方式,因为无需顾忌其是否和底层硬件兼容,比如Guest操作的是SCSI的设备,但实际物理机可以SATA的硬盘。虽然这种模拟I/O设备的做法有一定开支,但在经过了VMware长时间优化,使得其在处理小规模的I/O时,非常游刃有余,但是在这个模型的方法在处理大规模I/O的时候,有时候可能会出现力不从心的局面,所以VMware在I/O层推出一些半虚拟机技术,比如,vmxnet半虚拟化网卡。 其次,为了更好地为VM服务,VMKernel还支持一些高级I/O技术:
总结在开头也说,有可能是竞争的原因,使得VMware已经越来越少地公开它的技术资料,特别是最核心的ESX技术。 所以上面这些材料主要是来自于ESX 2的文档,而不是来自于最新的vSphere 4的文档,但是从这些文档中,我们还可以可以看出它绝对是全虚拟化的巅峰,并且在其新版中也已经引入了代号为VMI的半虚拟技术和支持Intel/AMD最新的硬件辅助虚拟化技术。就像本系列第二篇X86虚拟化技术所讲的那样,虽然在速度上面,半虚拟化技术和硬件辅助虚拟化技术的确各有千秋,但是他们都有软肋,半虚拟化技术是需要对Guest OS进行修改,硬件辅助虚拟化技术则是不够成熟,而且ESX的全虚拟化技术是经过VMware高级工程师们长达10年优化的,所以在跑某些Workload的时候,全虚拟化反而速度更优。综上所述,用户在使用最新版ESX的时候,应该根据不同的workload来选择不同的虚拟化方法,具体可以查看VMware的白皮书(见参3)。 本篇结束,下篇将关注Virtual Networking! 参考资料:
| |
|
(4个打分, 平均:5.00 / 5) |


柳传志 。乐Phone 。背水一战
作者 陈怀临 | 2010-04-27 02:51 | 类型 行业动感 | Comments Off
速评:联想乐Phone初体验之三喜和三憾
作者 老韩 | 2010-04-26 05:30 | 类型 行业动感 | 33条用户评论 »
|
原文发布于《计算机世界》,是乐Phone专题的配文。 笔者并不十分看好乐Phone,只有两个因素可能导致其成功:其一是“联想商店”的经营,其二是柳那句犀利的“这是在中国”。产业与商务层面的具体分析,请参见乐Phone专题。 ……曾经有3个手机摆在我面前:Broncho A1(Android)、LG GW880(OPhone)和联想乐Phone,最终笔者选择了A1。不用加期限了,随后带来A1的使用心得。
一喜:硬件配置相对领先,3.7英寸的触控屏,AMOLED材质显示屏幕,分辨率达到了WVGA级别 (800×480像素),高通QSD8250处理平台,运行频率达到了1GHz,操作感比较流畅。 二喜:配有标准3.5音频接口,要知道很多品牌手机在音频接口上都比较霸道,配备自家专用接口。标准的3.5音频接口意味着普通耳机即插即用,符合许多年轻人的口味。 三喜:与本土Web2.0服务提供商的紧密结合。乐Phone在系统中预置了30多种应用程序,包括开心网、新浪微博和支付宝等主流应用。要知道Google、中国移动和苹果都有自己的SaaS产品或增值服务,对应用程序的态度是有限的开放。联想站在完全的利益无关方角度,比较好地整合了大量国内主流Web2.0应用。 一憾:基于Android 1.6操作系统开发的“联想乐Phone操作系统平台”暂不支持多点触控,在iPhone上能用手指随意调整图片大小的“酷”劲在乐Phone上得不到体验,就这一项,手机迷们的兴趣就要大打折扣。 二憾:业界普遍叫好的独立“四叶草”UI界面在计世小编用来并不习惯,无按键操控体验较之iPhone还有差距。要知道,大多数用户在购买手机后并不会看说明书,能否快速上手,是手机能否大受欢迎的重要决定因素。 三憾:乐Phone的数据线/充电接口设计相当独特,连接处还采用了磁力设计,并外置了磁吸式金属保护盖。但这个保护盖和接口是完全分离的,很容易被粗心的用户弄丢,起码计世小编就好几次险些丢掉保护盖。 结语:不可否认,联想基于相对开源的Android系统开发了“联想乐Phone操作系统平台”,并在乐 Phone的硬件设计上下了大功夫。凭借对中低端市场的了解,乐Phone在年轻人和非商务人士中会比较受欢迎。 但是,要谈到和iPhone一较高下,乐Phone还有一段不小距离。我们来看看智能手机领域内各家的优势:Android本身是由Google推出,与Google基于云的SaaS产品做到无缝整合;Ophone的优势在于运营资源,与中国移动增值服务的无缝整合;iPhone则赢在品牌、理念和对用户的领导能力。从目前来看,复制iPhone的发展路线,占领年轻用户为主的中低端市场,似乎是乐 Phone惟一的出路。 未来,联想商店将会成为乐Phone成败的关键,这也是很多品牌厂商在智能手机遭遇滑铁卢的致命因素,如何聚集像 App Store那样的人气,如何探索出一套有利的营利模式,将决定乐Phone是否拥有持久的生命力。 | |
  (6个打分, 平均:3.50 / 5) (6个打分, 平均:3.50 / 5) |

城域网系列 – 5 ALU新ME的前世今生(IPTV 4)
作者 manjusri | 2010-04-26 01:18 | 类型 通讯产品 | 11条用户评论 »
系列目录 城域网系列
3、 频道监控 在IPTV的系统优化方案上,CISCO其实是走的最先的,但目前AL走在前头,可见思科在城域这块目前的投入情况,因此导致思科城域产品青黄不接(C76和ASR9K)的困境也不太难理解了。 IPTV的种种问题,来源于紧密融合型triple play对传统电视的传输改变太大,那么能否还是用独立通道的模式做IPTV,当然有人这么想并且这么做,就是美国的Verizon,通过FTTH,整个IPTV系统,单独用一个波长做IPTV,一根λ的管子到底,中间也不要什么啥子组播了,啥都生了。据说很成功,但是为不使用全球这么多运营商,毕竟FTTX的投入不是很多运营商能很快做到的。 具体在到AL的VPLS组播方案,本身也是非常复杂,比L3还复杂,所以还不如直接就L3组播到边缘,只是过去大家的惯性观点,再加上现在的供应商为了自己的方案和产品优势及多收钱考虑,把L3组播忽悠成比VPLS贵的方案,至于L3组播故障收敛慢的问题,目前已经有相对成熟的方案解决了,不是大问题。L3组播的主要问题是VPN的问题,组播VPN很复杂,而MPLS的P2MP组播技术最近才看是成熟,导致L3组播不能和MPLS很好的结合,有些不爽。在MPLS的组播方面,J做得最好 | |
|
(3个打分, 平均:3.67 / 5) |
论山寨手机与Android联姻的技术基础(全集)
作者 陈怀临 | 2010-04-25 15:27 | 类型 专题分析, 弯曲推荐, 移动和设备 | 16条用户评论 »
|
【陈怀临注:这篇“论山寨手机与Android联姻的技术基础”是我认为目前中文世界里对手机产业,特别是从技术的角度,对山寨机和Android分析得最好的文献。写作之严谨,功底之深厚,让人叹服。此中有真意,欲辩已忘言。由衷的感谢作者Sunny和Kan。读者可以下载全文论山寨手机与Android联姻的技术基础,也可以分章阅读:论山寨手机与Android】 | |
|
(15个打分, 平均:5.00 / 5) |

世博会 。网络 。安全
作者 陈怀临 | 2010-04-25 14:46 | 类型 行业动感 | 2条用户评论 »
城域网系列 – 5 ALU新ME的前世今生(IPTV 3)
作者 manjusri | 2010-04-25 09:58 | 类型 通讯产品 | 4条用户评论 »
系列目录 城域网系列
视频是带宽的主要占用者,所以说到IPTV,就要说一下带宽的问题,在有独立带宽保证的TV传输网络,网络本身基本上不需要提供什么QOS保证,这也符合internet的IP承载网带宽充足,就不需要QOS的观点。因为2001年的IT泡沫,带来了大量的骨干网光纤资源,而WDM技术的发展,目前已经超前IP流量,所以运营商的骨干网带宽到现在都不是问题,并且自有率很高,租用也比较容易,这都是托2001年IT泡沫的造福。但是在接入网方面,情况就完全不乐观了,而TV对接入网带宽要求较高,所以接入网带宽是IPTV的瓶颈。 IPTV虽然不那么好,但却是triple play的核心,所以也是AL新ME核心,主要包括如下内容: | |
|
(1个打分, 平均:5.00 / 5) |